 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTool Retrieval Bridge: Aligning Vague Instructions with Retriever Preferences via Bridge Model
Apr 09, 2026Tool learning has emerged as a promising paradigm for large language models (LLMs) to address real-world challenges. Due to the extensive and irregularly updated number of tools, tool retrieval for selecting the desired tool subset is essential. However, current tool retrieval methods are usually based on academic benchmarks containing overly detailed instructions (e.g., specific API names and parameters), while real-world instructions are more vague. Such a discrepancy would hinder the tool retrieval in real-world applications. In this paper, we first construct a new benchmark, VGToolBench, to simulate human vague instructions. Based on this, we conduct a series of preliminary analyses and find that vague instructions indeed damage the performance of tool retrieval. To this end, we propose a simple-yet-effective Tool Retrieval Bridge (TRB) approach to boost the performance of tool retrieval for vague instructions. The principle of TRB is to introduce a bridge model to rewrite the vague instructions into more specific ones and alleviate the gap between vague instructions and retriever preferences.We conduct extensive experiments under multiple commonly used retrieval settings, and the results show that TRB effectively mitigates the ambiguity of vague instructions while delivering consistent and substantial improvements across all baseline retrievers. For example, with the help of TRB, BM25 achieves a relative improvement of up to 111.51%, i.e., increasing the average NDCG score from 9.73 to 19.59. The source code and models are publicly available at https://github.com/kfchenhn/TRB.
ET-SAM: Efficient Point Prompt Prediction in SAM for Unified Scene Text Detection and Layout Analysis
Mar 26, 2026Previous works based on Segment Anything Model (SAM) have achieved promising performance in unified scene text detection and layout analysis. However, the typical reliance on pixel-level text segmentation for sampling thousands of foreground points as prompts leads to unsatisfied inference latency and limited data utilization. To address above issues, we propose ET-SAM, an Efficient framework with two decoders for unified scene Text detection and layout analysis based on SAM. Technically, we customize a lightweight point decoder that produces word heatmaps for achieving a few foreground points, thereby eliminating excessive point prompts and accelerating inference. Without the dependence on pixel-level segmentation, we further design a joint training strategy to leverage existing data with heterogeneous text-level annotations. Specifically, the datasets with multi-level, word-level only, and line-level only annotations are combined in parallel as a unified training set. For these datasets, we introduce three corresponding sets of learnable task prompts in both the point decoder and hierarchical mask decoder to mitigate discrepancies across datasets.Extensive experiments demonstrate that, compared to the previous SAM-based architecture, ET-SAM achieves about 3$\times$ inference acceleration while obtaining competitive performance on HierText, and improves an average of 11.0% F-score on Total-Text, CTW1500, and ICDAR15.
Try, Check and Retry: A Divide-and-Conquer Framework for Boosting Long-context Tool-Calling Performance of LLMs
Mar 12, 2026Tool-calling empowers Large Language Models (LLMs) to interact with external environments. However, current methods often struggle to handle massive and noisy candidate tools in long-context tool-calling tasks, limiting their real-world application. To this end, we propose Tool-DC, a Divide-and-Conquer framework for boosting tool-calling performance of LLMs. The core of Tool-DC is to reduce the reasoning difficulty and make full use of self-reflection ability of LLMs via a "Try-Check-Retry" paradigm. Specifically, Tool-DC involves two variants: 1) the training-free Tool-DC (TF), which is plug-and-play and flexible; 2) the training-based Tool-DC (TB), which is more inference-efficient. Extensive experiments show that both Tool-DC methods outperform their counterparts by a clear margin. Tool-DC (TF) brings up to +25.10% average gains against the baseline on BFCL and ACEBench benchmarks, while Tool-DC (TB) enables Qwen2.5-7B to achieve comparable or even better performance than proprietary LLMs, e.g., OpenAI o3 and Claude-Haiku-4.5.
LoSemB: Logic-Guided Semantic Bridging for Inductive Tool Retrieval
Aug 11, 2025Tool learning has emerged as a promising paradigm for large language models (LLMs) to solve many real-world tasks. Nonetheless, with the tool repository rapidly expanding, it is impractical to contain all tools within the limited input length of LLMs. To alleviate these issues, researchers have explored incorporating a tool retrieval module to select the most relevant tools or represent tools as unique tokens within LLM parameters. However, most state-of-the-art methods are under transductive settings, assuming all tools have been observed during training. Such a setting deviates from reality as the real-world tool repository is evolving and incorporates new tools frequently. When dealing with these unseen tools, which refer to tools not encountered during the training phase, these methods are limited by two key issues, including the large distribution shift and the vulnerability of similarity-based retrieval. To this end, inspired by human cognitive processes of mastering unseen tools through discovering and applying the logical information from prior experience, we introduce a novel Logic-Guided Semantic Bridging framework for inductive tool retrieval, namely, LoSemB, which aims to mine and transfer latent logical information for inductive tool retrieval without costly retraining. Specifically, LoSemB contains a logic-based embedding alignment module to mitigate distribution shifts and implements a relational augmented retrieval mechanism to reduce the vulnerability of similarity-based retrieval. Extensive experiments demonstrate that LoSemB achieves advanced performance in inductive settings while maintaining desirable effectiveness in the transductive setting.
Rethink Sparse Signals for Pose-guided Text-to-image Generation
Jun 26, 2025Recent works favored dense signals (e.g., depth, DensePose), as an alternative to sparse signals (e.g., OpenPose), to provide detailed spatial guidance for pose-guided text-to-image generation. However, dense representations raised new challenges, including editing difficulties and potential inconsistencies with textual prompts. This fact motivates us to revisit sparse signals for pose guidance, owing to their simplicity and shape-agnostic nature, which remains underexplored. This paper proposes a novel Spatial-Pose ControlNet(SP-Ctrl), equipping sparse signals with robust controllability for pose-guided image generation. Specifically, we extend OpenPose to a learnable spatial representation, making keypoint embeddings discriminative and expressive. Additionally, we introduce keypoint concept learning, which encourages keypoint tokens to attend to the spatial positions of each keypoint, thus improving pose alignment. Experiments on animal- and human-centric image generation tasks demonstrate that our method outperforms recent spatially controllable T2I generation approaches under sparse-pose guidance and even matches the performance of dense signal-based methods. Moreover, SP-Ctrl shows promising capabilities in diverse and cross-species generation through sparse signals. Codes will be available at https://github.com/DREAMXFAR/SP-Ctrl.
Adapting Segment Anything Model for Power Transmission Corridor Hazard Segmentation
May 28, 2025Power transmission corridor hazard segmentation (PTCHS) aims to separate transmission equipment and surrounding hazards from complex background, conveying great significance to maintaining electric power transmission safety. Recently, the Segment Anything Model (SAM) has emerged as a foundational vision model and pushed the boundaries of segmentation tasks. However, SAM struggles to deal with the target objects in complex transmission corridor scenario, especially those with fine structure. In this paper, we propose ELE-SAM, adapting SAM for the PTCHS task. Technically, we develop a Context-Aware Prompt Adapter to achieve better prompt tokens via incorporating global-local features and focusing more on key regions. Subsequently, to tackle the hazard objects with fine structure in complex background, we design a High-Fidelity Mask Decoder by leveraging multi-granularity mask features and then scaling them to a higher resolution. Moreover, to train ELE-SAM and advance this field, we construct the ELE-40K benchmark, the first large-scale and real-world dataset for PTCHS including 44,094 image-mask pairs. Experimental results for ELE-40K demonstrate the superior performance that ELE-SAM outperforms the baseline model with the average 16.8% mIoU and 20.6% mBIoU performance improvement. Moreover, compared with the state-of-the-art method on HQSeg-44K, the average 2.9% mIoU and 3.8% mBIoU absolute improvements further validate the effectiveness of our method on high-quality generic object segmentation. The source code and dataset are available at https://github.com/Hhaizee/ELE-SAM.
Resolving Knowledge Conflicts in Domain-specific Data Selection: A Case Study on Medical Instruction-tuning
May 28, 2025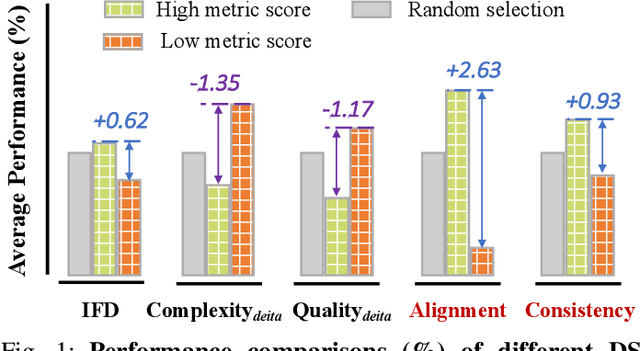
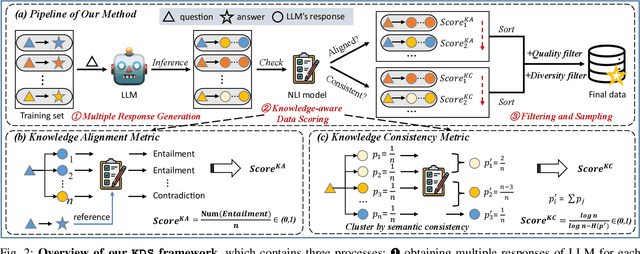
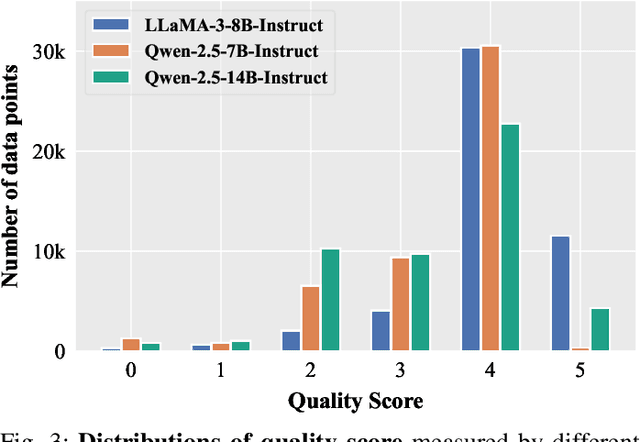
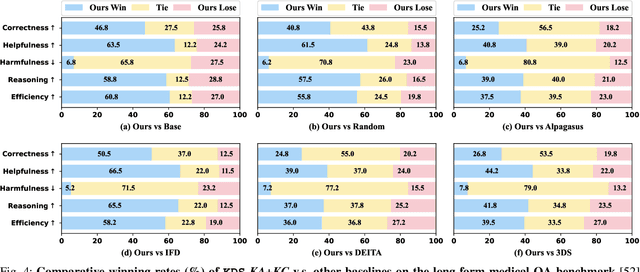
Domain-specific instruction-tuning has become the defacto standard for improving the performance of large language models (LLMs) in specialized applications, e.g., medical question answering. Since the instruction-tuning dataset might contain redundant or low-quality data, data selection (DS) is usually required to maximize the data efficiency. Despite the successes in the general domain, current DS methods often struggle to select the desired data for domain-specific instruction-tuning. One of the main reasons is that they neglect the impact of knowledge conflicts, i.e., the discrepancy between LLMs' pretrained knowledge and context knowledge of instruction data, which could damage LLMs' prior abilities and lead to hallucination. To this end, we propose a simple-yet-effective Knowledge-aware Data Selection (namely KDS) framework to select the domain-specific instruction-tuning data that meets LLMs' actual needs. The core of KDS is to leverage two knowledge-aware metrics for quantitatively measuring knowledge conflicts from two aspects: context-memory knowledge alignment and intra-memory knowledge consistency. By filtering the data with large knowledge conflicts and sampling the high-quality and diverse data, KDS can effectively stimulate the LLMs' abilities and achieve better domain-specific performance. Taking the medical domain as the testbed, we conduct extensive experiments and empirically prove that KDS surpasses the other baselines and brings significant and consistent performance gains among all LLMs. More encouragingly, KDS effectively improves the model generalization and alleviates the hallucination problem.
GoMatching++: Parameter- and Data-Efficient Arbitrary-Shaped Video Text Spotting and Benchmarking
May 28, 2025



Video text spotting (VTS) extends image text spotting (ITS) by adding text tracking, significantly increasing task complexity. Despite progress in VTS, existing methods still fall short of the performance seen in ITS. This paper identifies a key limitation in current video text spotters: limited recognition capability, even after extensive end-to-end training. To address this, we propose GoMatching++, a parameter- and data-efficient method that transforms an off-the-shelf image text spotter into a video specialist. The core idea lies in freezing the image text spotter and introducing a lightweight, trainable tracker, which can be optimized efficiently with minimal training data. Our approach includes two key components: (1) a rescoring mechanism to bridge the domain gap between image and video data, and (2) the LST-Matcher, which enhances the frozen image text spotter's ability to handle video text. We explore various architectures for LST-Matcher to ensure efficiency in both parameters and training data. As a result, GoMatching++ sets new performance records on challenging benchmarks such as ICDAR15-video, DSText, and BOVText, while significantly reducing training costs. To address the lack of curved text datasets in VTS, we introduce ArTVideo, a new benchmark featuring over 30% curved text with detailed annotations. We also provide a comprehensive statistical analysis and experimental results for ArTVideo. We believe that GoMatching++ and the ArTVideo benchmark will drive future advancements in video text spotting. The source code, models and dataset are publicly available at https://github.com/Hxyz-123/GoMatching.
KaFT: Knowledge-aware Fine-tuning for Boosting LLMs' Domain-specific Question-Answering Performance
May 21, 2025Supervised fine-tuning (SFT) is a common approach to improve the domain-specific question-answering (QA) performance of large language models (LLMs). However, recent literature reveals that due to the conflicts between LLMs' internal knowledge and the context knowledge of training data, vanilla SFT using the full QA training set is usually suboptimal. In this paper, we first design a query diversification strategy for robust conflict detection and then conduct a series of experiments to analyze the impact of knowledge conflict. We find that 1) training samples with varied conflicts contribute differently, where SFT on the data with large conflicts leads to catastrophic performance drops; 2) compared to directly filtering out the conflict data, appropriately applying the conflict data would be more beneficial. Motivated by this, we propose a simple-yet-effective Knowledge-aware Fine-tuning (namely KaFT) approach to effectively boost LLMs' performance. The core of KaFT is to adapt the training weight by assigning different rewards for different training samples according to conflict level. Extensive experiments show that KaFT brings consistent and significant improvements across four LLMs. More analyses prove that KaFT effectively improves the model generalization and alleviates the hallucination.
Reasoning-OCR: Can Large Multimodal Models Solve Complex Logical Reasoning Problems from OCR Cues?
May 19, 2025Large Multimodal Models (LMMs) have become increasingly versatile, accompanied by impressive Optical Character Recognition (OCR) related capabilities. Existing OCR-related benchmarks emphasize evaluating LMMs' abilities of relatively simple visual question answering, visual-text parsing, etc. However, the extent to which LMMs can deal with complex logical reasoning problems based on OCR cues is relatively unexplored. To this end, we introduce the Reasoning-OCR benchmark, which challenges LMMs to solve complex reasoning problems based on the cues that can be extracted from rich visual-text. Reasoning-OCR covers six visual scenarios and encompasses 150 meticulously designed questions categorized into six reasoning challenges. Additionally, Reasoning-OCR minimizes the impact of field-specialized knowledge. Our evaluation offers some insights for proprietary and open-source LMMs in different reasoning challenges, underscoring the urgent to improve the reasoning performance. We hope Reasoning-OCR can inspire and facilitate future research on enhancing complex reasoning ability based on OCR cues. Reasoning-OCR is publicly available at https://github.com/Hxyz-123/ReasoningOCR.