 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTri-Prompting: Video Diffusion with Unified Control over Scene, Subject, and Motion
Mar 16, 2026Recent video diffusion models have made remarkable strides in visual quality, yet precise, fine-grained control remains a key bottleneck that limits practical customizability for content creation. For AI video creators, three forms of control are crucial: (i) scene composition, (ii) multi-view consistent subject customization, and (iii) camera-pose or object-motion adjustment. Existing methods typically handle these dimensions in isolation, with limited support for multi-view subject synthesis and identity preservation under arbitrary pose changes. This lack of a unified architecture makes it difficult to support versatile, jointly controllable video. We introduce Tri-Prompting, a unified framework and two-stage training paradigm that integrates scene composition, multi-view subject consistency, and motion control. Our approach leverages a dual-condition motion module driven by 3D tracking points for background scenes and downsampled RGB cues for foreground subjects. To ensure a balance between controllability and visual realism, we further propose an inference ControlNet scale schedule. Tri-Prompting supports novel workflows, including 3D-aware subject insertion into any scenes and manipulation of existing subjects in an image. Experimental results demonstrate that Tri-Prompting significantly outperforms specialized baselines such as Phantom and DaS in multi-view subject identity, 3D consistency, and motion accuracy.
ZipIR: Latent Pyramid Diffusion Transformer for High-Resolution Image Restoration
Apr 11, 2025Recent progress in generative models has significantly improved image restoration capabilities, particularly through powerful diffusion models that offer remarkable recovery of semantic details and local fidelity. However, deploying these models at ultra-high resolutions faces a critical trade-off between quality and efficiency due to the computational demands of long-range attention mechanisms. To address this, we introduce ZipIR, a novel framework that enhances efficiency, scalability, and long-range modeling for high-res image restoration. ZipIR employs a highly compressed latent representation that compresses image 32x, effectively reducing the number of spatial tokens, and enabling the use of high-capacity models like the Diffusion Transformer (DiT). Toward this goal, we propose a Latent Pyramid VAE (LP-VAE) design that structures the latent space into sub-bands to ease diffusion training. Trained on full images up to 2K resolution, ZipIR surpasses existing diffusion-based methods, offering unmatched speed and quality in restoring high-resolution images from severely degraded inputs.
TurboFill: Adapting Few-step Text-to-image Model for Fast Image Inpainting
Apr 01, 2025This paper introduces TurboFill, a fast image inpainting model that enhances a few-step text-to-image diffusion model with an inpainting adapter for high-quality and efficient inpainting. While standard diffusion models generate high-quality results, they incur high computational costs. We overcome this by training an inpainting adapter on a few-step distilled text-to-image model, DMD2, using a novel 3-step adversarial training scheme to ensure realistic, structurally consistent, and visually harmonious inpainted regions. To evaluate TurboFill, we propose two benchmarks: DilationBench, which tests performance across mask sizes, and HumanBench, based on human feedback for complex prompts. Experiments show that TurboFill outperforms both multi-step BrushNet and few-step inpainting methods, setting a new benchmark for high-performance inpainting tasks. Our project page: https://liangbinxie.github.io/projects/TurboFill/
OmniPaint: Mastering Object-Oriented Editing via Disentangled Insertion-Removal Inpainting
Mar 12, 2025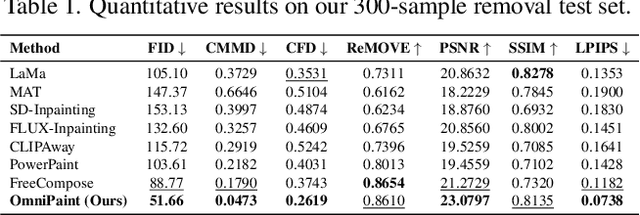

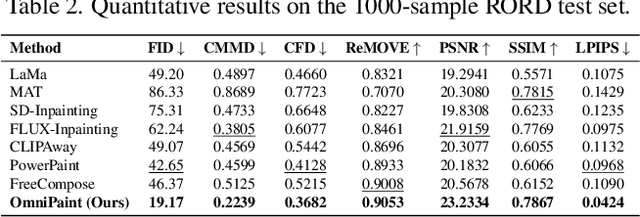

Diffusion-based generative models have revolutionized object-oriented image editing, yet their deployment in realistic object removal and insertion remains hampered by challenges such as the intricate interplay of physical effects and insufficient paired training data. In this work, we introduce OmniPaint, a unified framework that re-conceptualizes object removal and insertion as interdependent processes rather than isolated tasks. Leveraging a pre-trained diffusion prior along with a progressive training pipeline comprising initial paired sample optimization and subsequent large-scale unpaired refinement via CycleFlow, OmniPaint achieves precise foreground elimination and seamless object insertion while faithfully preserving scene geometry and intrinsic properties. Furthermore, our novel CFD metric offers a robust, reference-free evaluation of context consistency and object hallucination, establishing a new benchmark for high-fidelity image editing. Project page: https://yeates.github.io/OmniPaint-Page/
DOLLAR: Few-Step Video Generation via Distillation and Latent Reward Optimization
Dec 20, 2024Diffusion probabilistic models have shown significant progress in video generation; however, their computational efficiency is limited by the large number of sampling steps required. Reducing sampling steps often compromises video quality or generation diversity. In this work, we introduce a distillation method that combines variational score distillation and consistency distillation to achieve few-step video generation, maintaining both high quality and diversity. We also propose a latent reward model fine-tuning approach to further enhance video generation performance according to any specified reward metric. This approach reduces memory usage and does not require the reward to be differentiable. Our method demonstrates state-of-the-art performance in few-step generation for 10-second videos (128 frames at 12 FPS). The distilled student model achieves a score of 82.57 on VBench, surpassing the teacher model as well as baseline models Gen-3, T2V-Turbo, and Kling. One-step distillation accelerates the teacher model's diffusion sampling by up to 278.6 times, enabling near real-time generation. Human evaluations further validate the superior performance of our 4-step student models compared to teacher model using 50-step DDIM sampling.
MetaShadow: Object-Centered Shadow Detection, Removal, and Synthesis
Dec 03, 2024



Shadows are often under-considered or even ignored in image editing applications, limiting the realism of the edited results. In this paper, we introduce MetaShadow, a three-in-one versatile framework that enables detection, removal, and controllable synthesis of shadows in natural images in an object-centered fashion. MetaShadow combines the strengths of two cooperative components: Shadow Analyzer, for object-centered shadow detection and removal, and Shadow Synthesizer, for reference-based controllable shadow synthesis. Notably, we optimize the learning of the intermediate features from Shadow Analyzer to guide Shadow Synthesizer to generate more realistic shadows that blend seamlessly with the scene. Extensive evaluations on multiple shadow benchmark datasets show significant improvements of MetaShadow over the existing state-of-the-art methods on object-centered shadow detection, removal, and synthesis. MetaShadow excels in image-editing tasks such as object removal, relocation, and insertion, pushing the boundaries of object-centered image editing.
Object-level Scene Deocclusion
Jun 11, 2024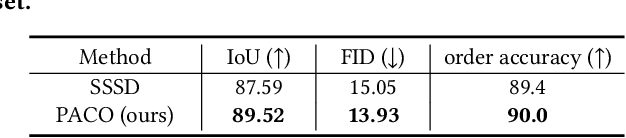

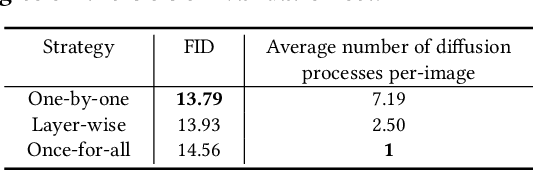
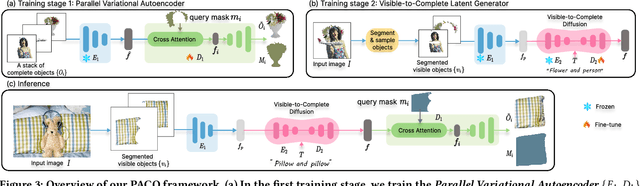
Deoccluding the hidden portions of objects in a scene is a formidable task, particularly when addressing real-world scenes. In this paper, we present a new self-supervised PArallel visible-to-COmplete diffusion framework, named PACO, a foundation model for object-level scene deocclusion. Leveraging the rich prior of pre-trained models, we first design the parallel variational autoencoder, which produces a full-view feature map that simultaneously encodes multiple complete objects, and the visible-to-complete latent generator, which learns to implicitly predict the full-view feature map from partial-view feature map and text prompts extracted from the incomplete objects in the input image. To train PACO, we create a large-scale dataset with 500k samples to enable self-supervised learning, avoiding tedious annotations of the amodal masks and occluded regions. At inference, we devise a layer-wise deocclusion strategy to improve efficiency while maintaining the deocclusion quality. Extensive experiments on COCOA and various real-world scenes demonstrate the superior capability of PACO for scene deocclusion, surpassing the state of the arts by a large margin. Our method can also be extended to cross-domain scenes and novel categories that are not covered by the training set. Further, we demonstrate the deocclusion applicability of PACO in single-view 3D scene reconstruction and object recomposition.
Jurassic World Remake: Bringing Ancient Fossils Back to Life via Zero-Shot Long Image-to-Image Translation
Aug 14, 2023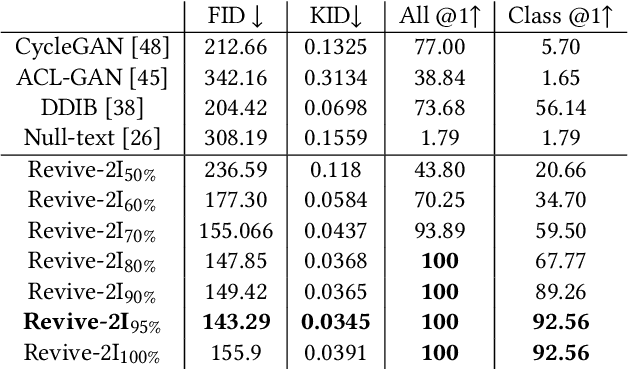
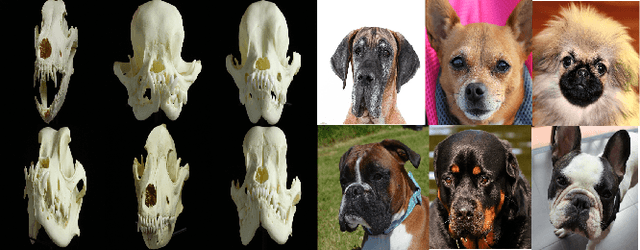
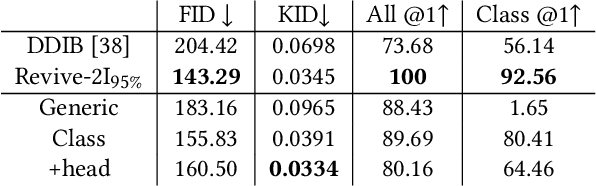
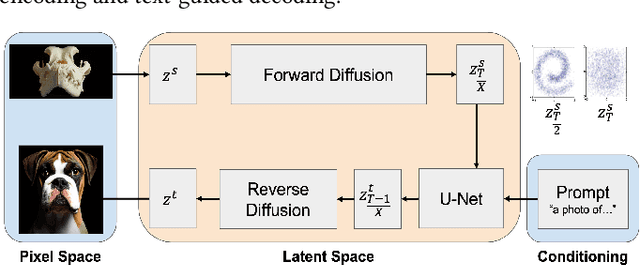
With a strong understanding of the target domain from natural language, we produce promising results in translating across large domain gaps and bringing skeletons back to life. In this work, we use text-guided latent diffusion models for zero-shot image-to-image translation (I2I) across large domain gaps (longI2I), where large amounts of new visual features and new geometry need to be generated to enter the target domain. Being able to perform translations across large domain gaps has a wide variety of real-world applications in criminology, astrology, environmental conservation, and paleontology. In this work, we introduce a new task Skull2Animal for translating between skulls and living animals. On this task, we find that unguided Generative Adversarial Networks (GANs) are not capable of translating across large domain gaps. Instead of these traditional I2I methods, we explore the use of guided diffusion and image editing models and provide a new benchmark model, Revive-2I, capable of performing zero-shot I2I via text-prompting latent diffusion models. We find that guidance is necessary for longI2I because, to bridge the large domain gap, prior knowledge about the target domain is needed. In addition, we find that prompting provides the best and most scalable information about the target domain as classifier-guided diffusion models require retraining for specific use cases and lack stronger constraints on the target domain because of the wide variety of images they are trained on.
Structure-Guided Image Completion with Image-level and Object-level Semantic Discriminators
Dec 13, 2022Structure-guided image completion aims to inpaint a local region of an image according to an input guidance map from users. While such a task enables many practical applications for interactive editing, existing methods often struggle to hallucinate realistic object instances in complex natural scenes. Such a limitation is partially due to the lack of semantic-level constraints inside the hole region as well as the lack of a mechanism to enforce realistic object generation. In this work, we propose a learning paradigm that consists of semantic discriminators and object-level discriminators for improving the generation of complex semantics and objects. Specifically, the semantic discriminators leverage pretrained visual features to improve the realism of the generated visual concepts. Moreover, the object-level discriminators take aligned instances as inputs to enforce the realism of individual objects. Our proposed scheme significantly improves the generation quality and achieves state-of-the-art results on various tasks, including segmentation-guided completion, edge-guided manipulation and panoptically-guided manipulation on Places2 datasets. Furthermore, our trained model is flexible and can support multiple editing use cases, such as object insertion, replacement, removal and standard inpainting. In particular, our trained model combined with a novel automatic image completion pipeline achieves state-of-the-art results on the standard inpainting task.
CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
Mar 22, 2022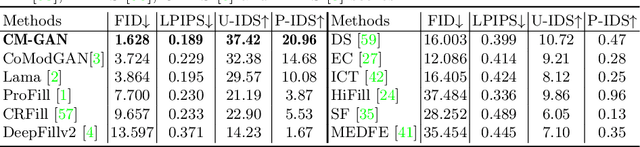
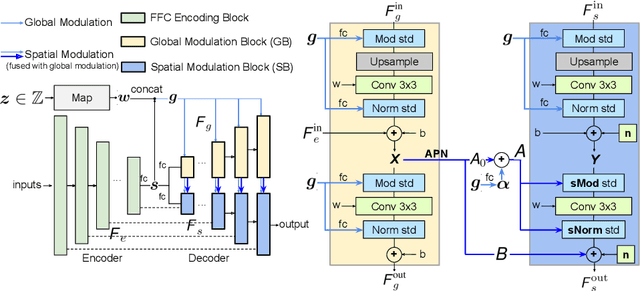
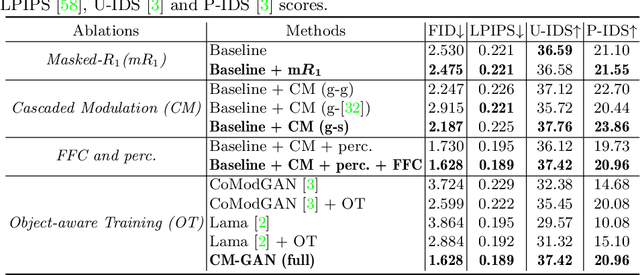

Recent image inpainting methods have made great progress but often struggle to generate plausible image structures when dealing with large holes in complex images. This is partially due to the lack of effective network structures that can capture both the long-range dependency and high-level semantics of an image. To address these problems, we propose cascaded modulation GAN (CM-GAN), a new network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a StyleGAN-like decoder with a novel cascaded global-spatial modulation block at each scale level. In each decoder block, global modulation is first applied to perform coarse semantic-aware structure synthesis, then spatial modulation is applied on the output of global modulation to further adjust the feature map in a spatially adaptive fashion. In addition, we design an object-aware training scheme to prevent the network from hallucinating new objects inside holes, fulfilling the needs of object removal tasks in real-world scenarios. Extensive experiments are conducted to show that our method significantly outperforms existing methods in both quantitative and qualitative evaluation.