 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Optimization for Black-Box Retrieval via Reinforcement Learning
Apr 06, 2026Document expansion is a classical technique for improving retrieval quality, and is attractive since it shifts computation offline, avoiding additional query-time processing. However, when applied to modern retrievers, it has been shown to degrade performance, often introducing noise that obfuscates the discriminative signal. We recast document expansion as a document optimization problem: a language model or a vision language model is fine-tuned to transform documents into representations that better align with the expected query distribution under a target retriever, using GRPO with the retriever's ranking improvements as rewards. This approach requires only black-box access to retrieval ranks, and is applicable across single-vector, multi-vector and lexical retrievers. We evaluate our approach on code retrieval and visual document retrieval (VDR) tasks. We find that learned document transformations yield retrieval gains and in many settings enable smaller, more efficient retrievers to outperform larger ones. For example, applying document optimization to OpenAI text-embedding-3-small model improves nDCG5 on code (58.7 to 66.8) and VDR (53.3 to 57.6), even slightly surpassing the 6.5X more expensive OpenAI text-embedding-3-large model (66.3 on code; 57.0 on VDR). When retriever weights are accessible, document optimization is often competitive with fine-tuning, and in most settings their combination performs best, improving Jina-ColBERT-V2 from 55.8 to 63.3 on VDR and from 48.6 to 61.8 on code retrieval.
Reflective Context Learning: Studying the Optimization Primitives of Context Space
Apr 03, 2026Generally capable agents must learn from experience in ways that generalize across tasks and environments. The fundamental problems of learning, including credit assignment, overfitting, forgetting, local optima, and high-variance learning signals, persist whether the learned object lies in parameter space or context space. While these challenges are well understood in classical machine learning optimization, they remain underexplored in context space, leading current methods to be fragmented and ad hoc. We present Reflective Context Learning (RCL), a unified framework for agents that learn through repeated interaction, reflection on behavior and failure modes, and iterative updates to context. In RCL, reflection converts trajectories and current context into a directional update signal analogous to gradients, while mutation applies that signal to improve future behavior in context space. We recast recent context-optimization approaches as instances of this shared learning problem and systematically extend them with classical optimization primitives, including batching, improved credit-assignment signal, auxiliary losses, failure replay, and grouped rollouts for variance reduction. On AppWorld, BrowseComp+, and RewardBench2, these primitives improve over strong baselines, with their relative importance shifting across task regimes. We further analyze robustness to initialization, the effects of batch size, sampling and curriculum strategy, optimizer-state variants, and the impact of allocating stronger or weaker models to different optimization components. Our results suggest that learning through context updates should be treated not as a set of isolated algorithms, but as an optimization problem whose mechanisms can be studied systematically and improved through transferable principles.
Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets
Apr 02, 2026Recent work reports strong performance from multi-agent LLM systems (MAS), but these gains are often confounded by increased test-time computation. When computation is normalized, single-agent systems (SAS) can match or outperform MAS, yet the theoretical basis and evaluation methodology behind this comparison remain unclear. We present an information-theoretic argument, grounded in the Data Processing Inequality, suggesting that under a fixed reasoning-token budget and with perfect context utilization, single-agent systems are more information-efficient. This perspective further predicts that multi-agent systems become competitive when a single agent's effective context utilization is degraded, or when more compute is expended. We test these predictions in a controlled empirical study across three model families (Qwen3, DeepSeek-R1-Distill-Llama, and Gemini 2.5), comparing SAS with multiple MAS architectures under matched budgets. We find that SAS consistently match or outperform MAS on multi-hop reasoning tasks when reasoning tokens are held constant. Beyond aggregate performance, we conduct a detailed diagnostic analysis of system behavior and evaluation methodology. We identify significant artifacts in API-based budget control (particularly in Gemini 2.5) and in standard benchmarks, both of which can inflate apparent gains from MAS. Overall, our results suggest that, for multi-hop reasoning tasks, many reported advantages of multi-agent systems are better explained by unaccounted computation and context effects rather than inherent architectural benefits, and highlight the importance of understanding and explicitly controlling the trade-offs between compute, context, and coordination in agentic systems.
ExtractBench: A Benchmark and Evaluation Methodology for Complex Structured Extraction
Feb 13, 2026Unstructured documents like PDFs contain valuable structured information, but downstream systems require this data in reliable, standardized formats. LLMs are increasingly deployed to automate this extraction, making accuracy and reliability paramount. However, progress is bottlenecked by two gaps. First, no end-to-end benchmark evaluates PDF-to-JSON extraction under enterprise-scale schema breadth. Second, no principled methodology captures the semantics of nested extraction, where fields demand different notions of correctness (exact match for identifiers, tolerance for quantities, semantic equivalence for names), arrays require alignment, and omission must be distinguished from hallucination. We address both gaps with ExtractBench, an open-source benchmark and evaluation framework for PDF-to-JSON structured extraction. The benchmark pairs 35 PDF documents with JSON Schemas and human-annotated gold labels across economically valuable domains, yielding 12,867 evaluatable fields spanning schema complexities from tens to hundreds of fields. The evaluation framework treats the schema as an executable specification: each field declares its scoring metric. Baseline evaluations reveal that frontier models (GPT-5/5.2, Gemini-3 Flash/Pro, Claude 4.5 Opus/Sonnet) remain unreliable on realistic schemas. Performance degrades sharply with schema breadth, culminating in 0% valid output on a 369-field financial reporting schema across all tested models. We release ExtractBench at https://github.com/ContextualAI/extract-bench.
BLITZRANK: Principled Zero-shot Ranking Agents with Tournament Graphs
Feb 05, 2026Large language models have emerged as powerful zero-shot rerankers for retrieval-augmented generation, offering strong generalization without task-specific training. However, existing LLM reranking methods either rely on heuristics that fail to fully exploit the information revealed by each ranking decision or are inefficient when they do. We introduce a tournament graph framework that provides a principled foundation for $k$-wise reranking. Our key observation is that each $k$-document comparison reveals a complete tournament of $\binom{k}{2}$ pairwise preferences. These tournaments are aggregated into a global preference graph, whose transitive closure yields many additional orderings without further model invocations. We formalize when a candidate's rank is certifiably determined and design a query schedule that greedily maximizes information gain towards identifying the top-$m$ items. Our framework also gracefully handles non-transitive preferences - cycles induced by LLM judgments - by collapsing them into equivalence classes that yield principled tiered rankings. Empirically, across 14 benchmarks and 5 LLMs, our method achieves Pareto dominance over existing methods: matching or exceeding accuracy while requiring 25-40% fewer tokens than comparable approaches, and 7$\times$ fewer than pairwise methods at near-identical quality.
Great Models Think Alike and this Undermines AI Oversight
Feb 06, 2025As Language Model (LM) capabilities advance, evaluating and supervising them at scale is getting harder for humans. There is hope that other language models can automate both these tasks, which we refer to as "AI Oversight". We study how model similarity affects both aspects of AI oversight by proposing a probabilistic metric for LM similarity based on overlap in model mistakes. Using this metric, we first show that LLM-as-a-judge scores favor models similar to the judge, generalizing recent self-preference results. Then, we study training on LM annotations, and find complementary knowledge between the weak supervisor and strong student model plays a crucial role in gains from "weak-to-strong generalization". As model capabilities increase, it becomes harder to find their mistakes, and we might defer more to AI oversight. However, we observe a concerning trend -- model mistakes are becoming more similar with increasing capabilities, pointing to risks from correlated failures. Our work underscores the importance of reporting and correcting for model similarity, especially in the emerging paradigm of AI oversight.
LMUnit: Fine-grained Evaluation with Natural Language Unit Tests
Dec 17, 2024As language models become integral to critical workflows, assessing their behavior remains a fundamental challenge -- human evaluation is costly and noisy, while automated metrics provide only coarse, difficult-to-interpret signals. We introduce natural language unit tests, a paradigm that decomposes response quality into explicit, testable criteria, along with a unified scoring model, LMUnit, which combines multi-objective training across preferences, direct ratings, and natural language rationales. Through controlled human studies, we show this paradigm significantly improves inter-annotator agreement and enables more effective LLM development workflows. LMUnit achieves state-of-the-art performance on evaluation benchmarks (FLASK, BigGenBench) and competitive results on RewardBench. These results validate both our proposed paradigm and scoring model, suggesting a promising path forward for language model evaluation and development.
Nearest Neighbor Normalization Improves Multimodal Retrieval
Oct 31, 2024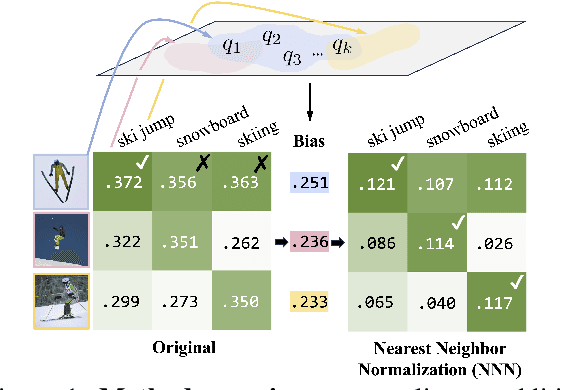



Multimodal models leverage large-scale pre-training to achieve strong but still imperfect performance on tasks such as image captioning, visual question answering, and cross-modal retrieval. In this paper, we present a simple and efficient method for correcting errors in trained contrastive image-text retrieval models with no additional training, called Nearest Neighbor Normalization (NNN). We show an improvement on retrieval metrics in both text retrieval and image retrieval for all of the contrastive models that we tested (CLIP, BLIP, ALBEF, SigLIP, BEiT) and for both of the datasets that we used (MS-COCO and Flickr30k). NNN requires a reference database, but does not require any training on this database, and can even increase the retrieval accuracy of a model after finetuning.
OLMoE: Open Mixture-of-Experts Language Models
Sep 03, 2024



We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.
Anchored Preference Optimization and Contrastive Revisions: Addressing Underspecification in Alignment
Aug 12, 2024



Large Language Models (LLMs) are often aligned using contrastive alignment objectives and preference pair datasets. The interaction between model, paired data, and objective makes alignment a complicated procedure, sometimes producing subpar results. We study this and find that (i) preference data gives a better learning signal when the underlying responses are contrastive, and (ii) alignment objectives lead to better performance when they specify more control over the model during training. Based on these insights, we introduce Contrastive Learning from AI Revisions (CLAIR), a data-creation method which leads to more contrastive preference pairs, and Anchored Preference Optimization (APO), a controllable and more stable alignment objective. We align Llama-3-8B-Instruct using various comparable datasets and alignment objectives and measure MixEval-Hard scores, which correlate highly with human judgments. The CLAIR preferences lead to the strongest performance out of all datasets, and APO consistently outperforms less controllable objectives. Our best model, trained on 32K CLAIR preferences with APO, improves Llama-3-8B-Instruct by 7.65%, closing the gap with GPT4-turbo by 45%. Our code is available at https://github.com/ContextualAI/CLAIR_and_APO.