 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectoryMover: Generative Movement of Object Trajectories in Videos
Mar 31, 2026Generative video editing has enabled several intuitive editing operations for short video clips that would previously have been difficult to achieve, especially for non-expert editors. Existing methods focus on prescribing an object's 3D or 2D motion trajectory in a video, or on altering the appearance of an object or a scene, while preserving both the video's plausibility and identity. Yet a method to move an object's 3D motion trajectory in a video, i.e., moving an object while preserving its relative 3D motion, is currently still missing. The main challenge lies in obtaining paired video data for this scenario. Previous methods typically rely on clever data generation approaches to construct plausible paired data from unpaired videos, but this approach fails if one of the videos in a pair can not easily be constructed from the other. Instead, we introduce TrajectoryAtlas, a new data generation pipeline for large-scale synthetic paired video data and a video generator TrajectoryMover fine-tuned with this data. We show that this successfully enables generative movement of object trajectories. Project page: https://chhatrekiran.github.io/trajectorymover
LoST: Level of Semantics Tokenization for 3D Shapes
Mar 18, 2026Tokenization is a fundamental technique in the generative modeling of various modalities. In particular, it plays a critical role in autoregressive (AR) models, which have recently emerged as a compelling option for 3D generation. However, optimal tokenization of 3D shapes remains an open question. State-of-the-art (SOTA) methods primarily rely on geometric level-of-detail (LoD) hierarchies, originally designed for rendering and compression. These spatial hierarchies are often token-inefficient and lack semantic coherence for AR modeling. We propose Level-of-Semantics Tokenization (LoST), which orders tokens by semantic salience, such that early prefixes decode into complete, plausible shapes that possess principal semantics, while subsequent tokens refine instance-specific geometric and semantic details. To train LoST, we introduce Relational Inter-Distance Alignment (RIDA), a novel 3D semantic alignment loss that aligns the relational structure of the 3D shape latent space with that of the semantic DINO feature space. Experiments show that LoST achieves SOTA reconstruction, surpassing previous LoD-based 3D shape tokenizers by large margins on both geometric and semantic reconstruction metrics. Moreover, LoST achieves efficient, high-quality AR 3D generation and enables downstream tasks like semantic retrieval, while using only 0.1%-10% of the tokens needed by prior AR models.
WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
Mar 17, 2026Recent advances in video diffusion transformers have enabled interactive gaming world models that allow users to explore generated environments over extended horizons. However, existing approaches struggle with precise action control and long-horizon 3D consistency. Most prior works treat user actions as abstract conditioning signals, overlooking the fundamental geometric coupling between actions and the 3D world, whereby actions induce relative camera motions that accumulate into a global camera pose within a 3D world. In this paper, we establish camera pose as a unifying geometric representation to jointly ground immediate action control and long-term 3D consistency. First, we define a physics-based continuous action space and represent user inputs in the Lie algebra to derive precise 6-DoF camera poses, which are injected into the generative model via a camera embedder to ensure accurate action alignment. Second, we use global camera poses as spatial indices to retrieve relevant past observations, enabling geometrically consistent revisiting of locations during long-horizon navigation. To support this research, we introduce a large-scale dataset comprising 3,000 minutes of authentic human gameplay annotated with camera trajectories and textual descriptions. Extensive experiments show that our approach substantially outperforms state-of-the-art interactive gaming world models in action controllability, long-horizon visual quality, and 3D spatial consistency.
Memory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
Jan 22, 2026Recent foundational video-to-video diffusion models have achieved impressive results in editing user provided videos by modifying appearance, motion, or camera movement. However, real-world video editing is often an iterative process, where users refine results across multiple rounds of interaction. In this multi-turn setting, current video editors struggle to maintain cross-consistency across sequential edits. In this work, we tackle, for the first time, the problem of cross-consistency in multi-turn video editing and introduce Memory-V2V, a simple, yet effective framework that augments existing video-to-video models with explicit memory. Given an external cache of previously edited videos, Memory-V2V employs accurate retrieval and dynamic tokenization strategies to condition the current editing step on prior results. To further mitigate redundancy and computational overhead, we propose a learnable token compressor within the DiT backbone that compresses redundant conditioning tokens while preserving essential visual cues, achieving an overall speedup of 30%. We validate Memory-V2V on challenging tasks including video novel view synthesis and text-conditioned long video editing. Extensive experiments show that Memory-V2V produces videos that are significantly more cross-consistent with minimal computational overhead, while maintaining or even improving task-specific performance over state-of-the-art baselines. Project page: https://dohunlee1.github.io/MemoryV2V
V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
Dec 12, 2025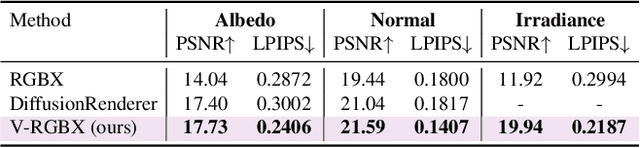
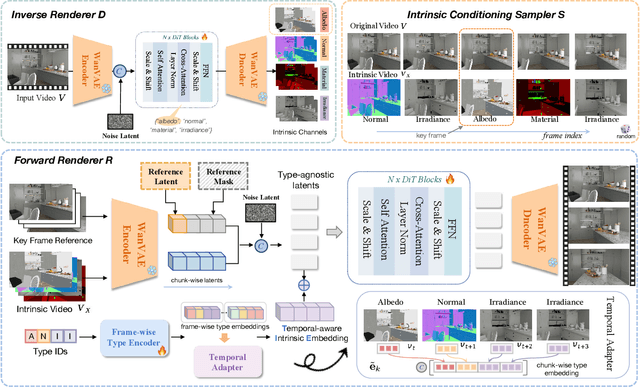
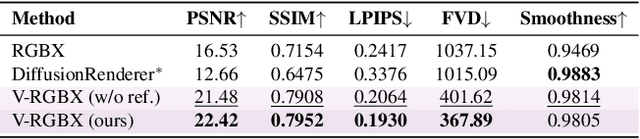

Large-scale video generation models have shown remarkable potential in modeling photorealistic appearance and lighting interactions in real-world scenes. However, a closed-loop framework that jointly understands intrinsic scene properties (e.g., albedo, normal, material, and irradiance), leverages them for video synthesis, and supports editable intrinsic representations remains unexplored. We present V-RGBX, the first end-to-end framework for intrinsic-aware video editing. V-RGBX unifies three key capabilities: (1) video inverse rendering into intrinsic channels, (2) photorealistic video synthesis from these intrinsic representations, and (3) keyframe-based video editing conditioned on intrinsic channels. At the core of V-RGBX is an interleaved conditioning mechanism that enables intuitive, physically grounded video editing through user-selected keyframes, supporting flexible manipulation of any intrinsic modality. Extensive qualitative and quantitative results show that V-RGBX produces temporally consistent, photorealistic videos while propagating keyframe edits across sequences in a physically plausible manner. We demonstrate its effectiveness in diverse applications, including object appearance editing and scene-level relighting, surpassing the performance of prior methods.
HUMOTO: A 4D Dataset of Mocap Human Object Interactions
Apr 14, 2025We present Human Motions with Objects (HUMOTO), a high-fidelity dataset of human-object interactions for motion generation, computer vision, and robotics applications. Featuring 736 sequences (7,875 seconds at 30 fps), HUMOTO captures interactions with 63 precisely modeled objects and 72 articulated parts. Our innovations include a scene-driven LLM scripting pipeline creating complete, purposeful tasks with natural progression, and a mocap-and-camera recording setup to effectively handle occlusions. Spanning diverse activities from cooking to outdoor picnics, HUMOTO preserves both physical accuracy and logical task flow. Professional artists rigorously clean and verify each sequence, minimizing foot sliding and object penetrations. We also provide benchmarks compared to other datasets. HUMOTO's comprehensive full-body motion and simultaneous multi-object interactions address key data-capturing challenges and provide opportunities to advance realistic human-object interaction modeling across research domains with practical applications in animation, robotics, and embodied AI systems. Project: https://jiaxin-lu.github.io/humoto/ .
Shape My Moves: Text-Driven Shape-Aware Synthesis of Human Motions
Apr 04, 2025



We explore how body shapes influence human motion synthesis, an aspect often overlooked in existing text-to-motion generation methods due to the ease of learning a homogenized, canonical body shape. However, this homogenization can distort the natural correlations between different body shapes and their motion dynamics. Our method addresses this gap by generating body-shape-aware human motions from natural language prompts. We utilize a finite scalar quantization-based variational autoencoder (FSQ-VAE) to quantize motion into discrete tokens and then leverage continuous body shape information to de-quantize these tokens back into continuous, detailed motion. Additionally, we harness the capabilities of a pretrained language model to predict both continuous shape parameters and motion tokens, facilitating the synthesis of text-aligned motions and decoding them into shape-aware motions. We evaluate our method quantitatively and qualitatively, and also conduct a comprehensive perceptual study to demonstrate its efficacy in generating shape-aware motions.
VideoHandles: Editing 3D Object Compositions in Videos Using Video Generative Priors
Mar 03, 2025Generative methods for image and video editing use generative models as priors to perform edits despite incomplete information, such as changing the composition of 3D objects shown in a single image. Recent methods have shown promising composition editing results in the image setting, but in the video setting, editing methods have focused on editing object's appearance and motion, or camera motion, and as a result, methods to edit object composition in videos are still missing. We propose \name as a method for editing 3D object compositions in videos of static scenes with camera motion. Our approach allows editing the 3D position of a 3D object across all frames of a video in a temporally consistent manner. This is achieved by lifting intermediate features of a generative model to a 3D reconstruction that is shared between all frames, editing the reconstruction, and projecting the features on the edited reconstruction back to each frame. To the best of our knowledge, this is the first generative approach to edit object compositions in videos. Our approach is simple and training-free, while outperforming state-of-the-art image editing baselines.
On Unifying Video Generation and Camera Pose Estimation
Jan 02, 2025



Inspired by the emergent 3D capabilities in image generators, we explore whether video generators similarly exhibit 3D awareness. Using structure-from-motion (SfM) as a benchmark for 3D tasks, we investigate if intermediate features from OpenSora, a video generation model, can support camera pose estimation. We first examine native 3D awareness in video generation features by routing raw intermediate outputs to SfM-prediction modules like DUSt3R. Then, we explore the impact of fine-tuning on camera pose estimation to enhance 3D awareness. Results indicate that while video generator features have limited inherent 3D awareness, task-specific supervision significantly boosts their accuracy for camera pose estimation, resulting in competitive performance. The proposed unified model, named JOG3R, produces camera pose estimates with competitive quality without degrading video generation quality.
Track4Gen: Teaching Video Diffusion Models to Track Points Improves Video Generation
Dec 10, 2024While recent foundational video generators produce visually rich output, they still struggle with appearance drift, where objects gradually degrade or change inconsistently across frames, breaking visual coherence. We hypothesize that this is because there is no explicit supervision in terms of spatial tracking at the feature level. We propose Track4Gen, a spatially aware video generator that combines video diffusion loss with point tracking across frames, providing enhanced spatial supervision on the diffusion features. Track4Gen merges the video generation and point tracking tasks into a single network by making minimal changes to existing video generation architectures. Using Stable Video Diffusion as a backbone, Track4Gen demonstrates that it is possible to unify video generation and point tracking, which are typically handled as separate tasks. Our extensive evaluations show that Track4Gen effectively reduces appearance drift, resulting in temporally stable and visually coherent video generation. Project page: hyeonho99.github.io/track4gen