 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatalogue Grounded Multimodal Attribution for Museum Video under Resource and Regulatory Constraints
Mar 11, 2026Audiovisual (AV) archives in museums and galleries are growing rapidly, but much of this material remains effectively locked away because it lacks consistent, searchable metadata. Existing method for archiving requires extensive manual effort. We address this by automating the most labour intensive part of the workflow: catalogue style metadata curation for in gallery video, grounded in an existing collection database. Concretely, we propose catalogue-grounded multimodal attribution for museum AV content using an open, locally deployable video language model. We design a multi pass pipeline that (i) summarises artworks in a video, (ii) generates catalogue style descriptions and genre labels, and (iii) attempts to attribute title and artist via conservative similarity matching to the structured catalogue. Early deployments on a painting catalogue suggest that this framework can improve AV archive discoverability while respecting resource constraints, data sovereignty, and emerging regulation, offering a transferable template for application-driven machine learning in other high-stakes domains.
Risk Estimation of Knee Osteoarthritis Progression via Predictive Multi-task Modelling from Efficient Diffusion Model using X-ray Images
Jun 17, 2025Medical imaging plays a crucial role in assessing knee osteoarthritis (OA) risk by enabling early detection and disease monitoring. Recent machine learning methods have improved risk estimation (i.e., predicting the likelihood of disease progression) and predictive modelling (i.e., the forecasting of future outcomes based on current data) using medical images, but clinical adoption remains limited due to their lack of interpretability. Existing approaches that generate future images for risk estimation are complex and impractical. Additionally, previous methods fail to localize anatomical knee landmarks, limiting interpretability. We address these gaps with a new interpretable machine learning method to estimate the risk of knee OA progression via multi-task predictive modelling that classifies future knee OA severity and predicts anatomical knee landmarks from efficiently generated high-quality future images. Such image generation is achieved by leveraging a diffusion model in a class-conditioned latent space to forecast disease progression, offering a visual representation of how particular health conditions may evolve. Applied to the Osteoarthritis Initiative dataset, our approach improves the state-of-the-art (SOTA) by 2\%, achieving an AUC of 0.71 in predicting knee OA progression while offering ~9% faster inference time.
Optimized 3D Gaussian Splatting using Coarse-to-Fine Image Frequency Modulation
Mar 18, 2025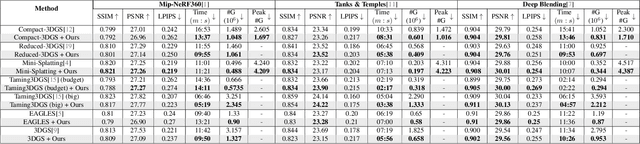
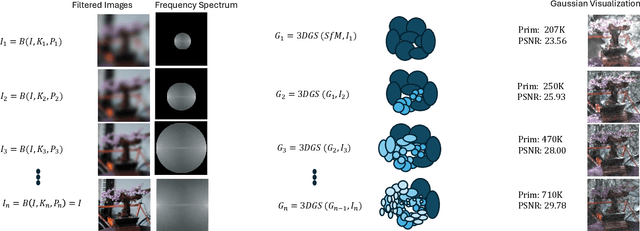
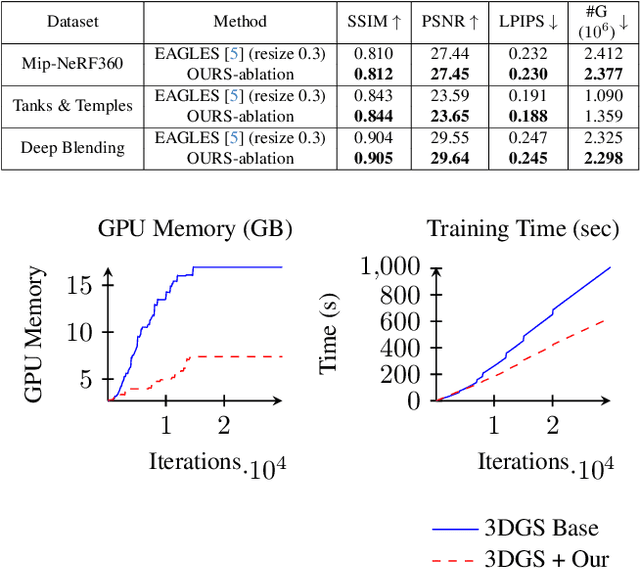

The field of Novel View Synthesis has been revolutionized by 3D Gaussian Splatting (3DGS), which enables high-quality scene reconstruction that can be rendered in real-time. 3DGS-based techniques typically suffer from high GPU memory and disk storage requirements which limits their practical application on consumer-grade devices. We propose Opti3DGS, a novel frequency-modulated coarse-to-fine optimization framework that aims to minimize the number of Gaussian primitives used to represent a scene, thus reducing memory and storage demands. Opti3DGS leverages image frequency modulation, initially enforcing a coarse scene representation and progressively refining it by modulating frequency details in the training images. On the baseline 3DGS, we demonstrate an average reduction of 62% in Gaussians, a 40% reduction in the training GPU memory requirements and a 20% reduction in optimization time without sacrificing the visual quality. Furthermore, we show that our method integrates seamlessly with many 3DGS-based techniques, consistently reducing the number of Gaussian primitives while maintaining, and often improving, visual quality. Additionally, Opti3DGS inherently produces a level-of-detail scene representation at no extra cost, a natural byproduct of the optimization pipeline. Results and code will be made publicly available.
Enhanced Multi-View Pedestrian Detection Using Probabilistic Occupancy Volume
Mar 14, 2025Occlusion poses a significant challenge in pedestrian detection from a single view. To address this, multi-view detection systems have been utilized to aggregate information from multiple perspectives. Recent advances in multi-view detection utilized an early-fusion strategy that strategically projects the features onto the ground plane, where detection analysis is performed. A promising approach in this context is the use of 3D feature-pulling technique, which constructs a 3D feature volume of the scene by sampling the corresponding 2D features for each voxel. However, it creates a 3D feature volume of the whole scene without considering the potential locations of pedestrians. In this paper, we introduce a novel model that efficiently leverages traditional 3D reconstruction techniques to enhance deep multi-view pedestrian detection. This is accomplished by complementing the 3D feature volume with probabilistic occupancy volume, which is constructed using the visual hull technique. The probabilistic occupancy volume focuses the model's attention on regions occupied by pedestrians and improves detection accuracy. Our model outperforms state-of-the-art models on the MultiviewX dataset, with an MODA of 97.3%, while achieving competitive performance on the Wildtrack dataset.
Joint Reconstruction of Spatially-Coherent and Realistic Clothed Humans and Objects from a Single Image
Feb 25, 2025
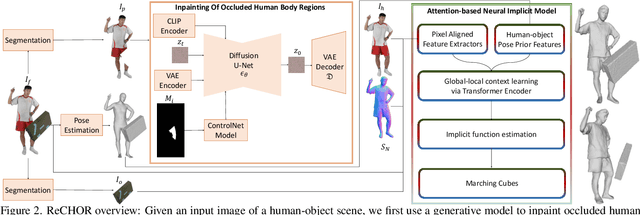
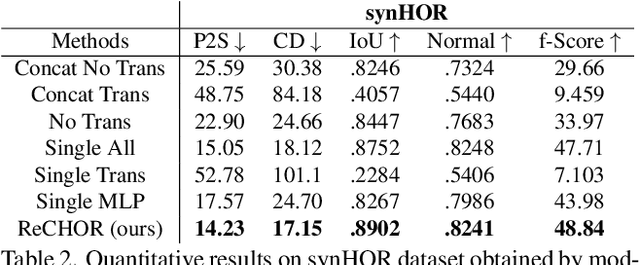
Recent advances in human shape learning have focused on achieving accurate human reconstruction from single-view images. However, in the real world, humans share space with other objects. Reconstructing images with humans and objects is challenging due to the occlusions and lack of 3D spatial awareness, which leads to depth ambiguity in the reconstruction. Existing methods in monocular human-object reconstruction fail to capture intricate details of clothed human bodies and object surfaces due to their template-based nature. In this paper, we jointly reconstruct clothed humans and objects in a spatially coherent manner from single-view images, while addressing human-object occlusions. A novel attention-based neural implicit model is proposed that leverages image pixel alignment to retrieve high-quality details, and incorporates semantic features extracted from the human-object pose to enable 3D spatial awareness. A generative diffusion model is used to handle human-object occlusions. For training and evaluation, we introduce a synthetic dataset with rendered scenes of inter-occluded 3D human scans and diverse objects. Extensive evaluation on both synthetic and real datasets demonstrates the superior quality of proposed human-object reconstructions over competitive methods.
Deconstruct Complexity (DeComplex): A Novel Perspective on Tackling Dense Action Detection
Jan 30, 2025Dense action detection involves detecting multiple co-occurring actions in an untrimmed video while action classes are often ambiguous and represent overlapping concepts. To address this challenge task, we introduce a novel perspective inspired by how humans tackle complex tasks by breaking them into manageable sub-tasks. Instead of relying on a single network to address the entire problem, as in current approaches, we propose decomposing the problem into detecting key concepts present in action classes, specifically, detecting dense static concepts and detecting dense dynamic concepts, and assigning them to distinct, specialized networks. Furthermore, simultaneous actions in a video often exhibit interrelationships, and exploiting these relationships can improve performance. However, we argue that current networks fail to effectively learn these relationships due to their reliance on binary cross-entropy optimization, which treats each class independently. To address this limitation, we propose providing explicit supervision on co-occurring concepts during network optimization through a novel language-guided contrastive learning loss. Our extensive experiments demonstrate the superiority of our approach over state-of-the-art methods, achieving substantial relative improvements of 23.4% and 2.5% mAP on the challenging benchmark datasets, Charades and MultiTHUMOS.
360U-Former: HDR Illumination Estimation with Panoramic Adapted Vision Transformers
Oct 17, 2024
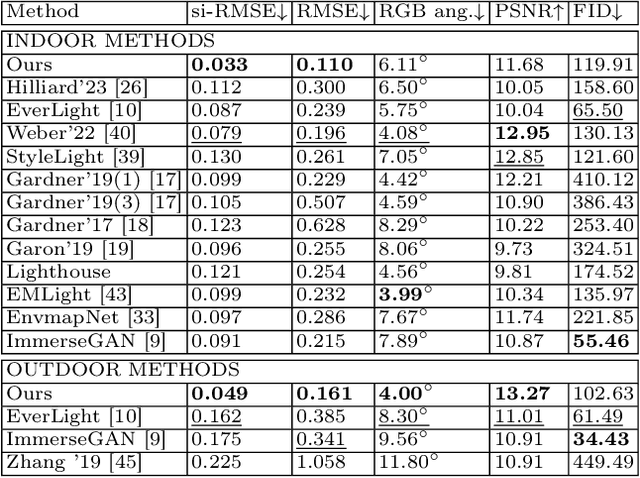
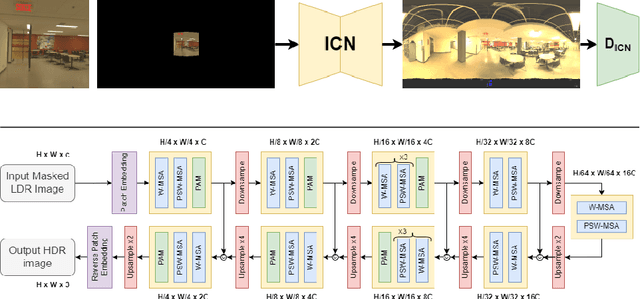
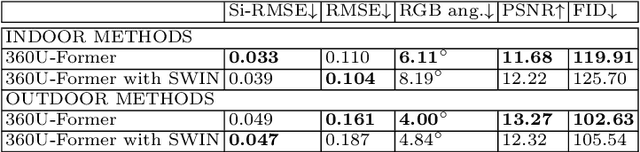
Recent illumination estimation methods have focused on enhancing the resolution and improving the quality and diversity of the generated textures. However, few have explored tailoring the neural network architecture to the Equirectangular Panorama (ERP) format utilised in image-based lighting. Consequently, high dynamic range images (HDRI) results usually exhibit a seam at the side borders and textures or objects that are warped at the poles. To address this shortcoming we propose a novel architecture, 360U-Former, based on a U-Net style Vision-Transformer which leverages the work of PanoSWIN, an adapted shifted window attention tailored to the ERP format. To the best of our knowledge, this is the first purely Vision-Transformer model used in the field of illumination estimation. We train 360U-Former as a GAN to generate HDRI from a limited field of view low dynamic range image (LDRI). We evaluate our method using current illumination estimation evaluation protocols and datasets, demonstrating that our approach outperforms existing and state-of-the-art methods without the artefacts typically associated with the use of the ERP format.
COSMU: Complete 3D human shape from monocular unconstrained images
Jul 15, 2024
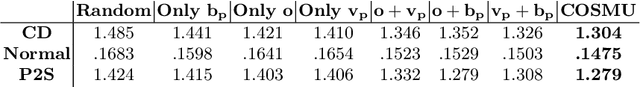
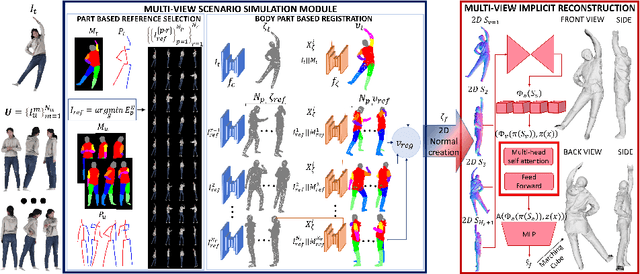
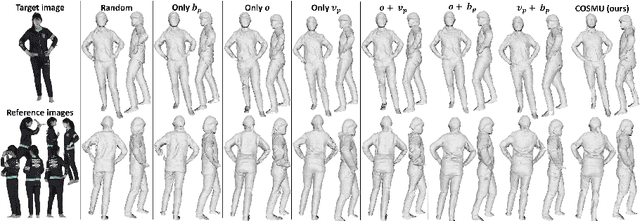
We present a novel framework to reconstruct complete 3D human shapes from a given target image by leveraging monocular unconstrained images. The objective of this work is to reproduce high-quality details in regions of the reconstructed human body that are not visible in the input target. The proposed methodology addresses the limitations of existing approaches for reconstructing 3D human shapes from a single image, which cannot reproduce shape details in occluded body regions. The missing information of the monocular input can be recovered by using multiple views captured from multiple cameras. However, multi-view reconstruction methods necessitate accurately calibrated and registered images, which can be challenging to obtain in real-world scenarios. Given a target RGB image and a collection of multiple uncalibrated and unregistered images of the same individual, acquired using a single camera, we propose a novel framework to generate complete 3D human shapes. We introduce a novel module to generate 2D multi-view normal maps of the person registered with the target input image. The module consists of body part-based reference selection and body part-based registration. The generated 2D normal maps are then processed by a multi-view attention-based neural implicit model that estimates an implicit representation of the 3D shape, ensuring the reproduction of details in both observed and occluded regions. Extensive experiments demonstrate that the proposed approach estimates higher quality details in the non-visible regions of the 3D clothed human shapes compared to related methods, without using parametric models.
Benchmarking Monocular 3D Dog Pose Estimation Using In-The-Wild Motion Capture Data
Jun 20, 2024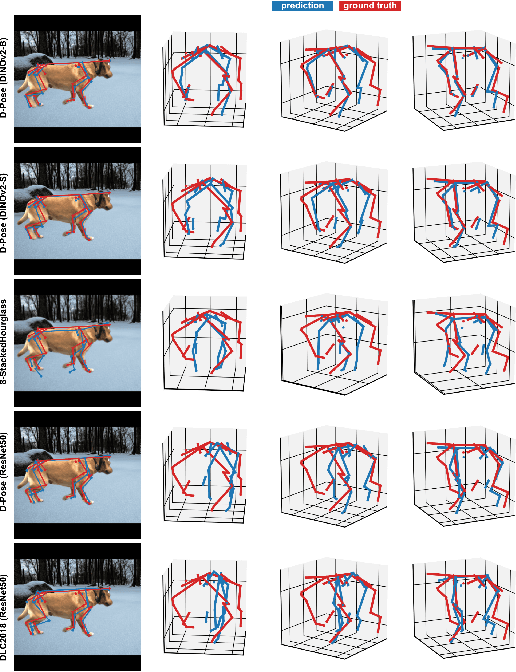
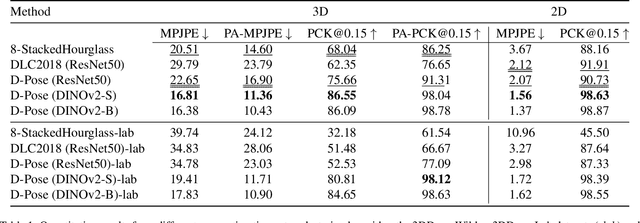

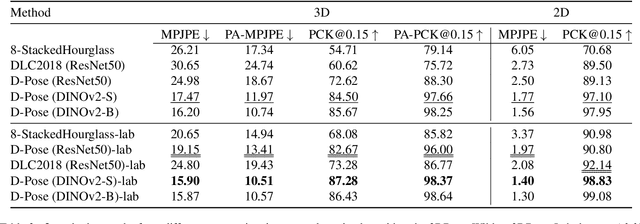
We introduce a new benchmark analysis focusing on 3D canine pose estimation from monocular in-the-wild images. A multi-modal dataset 3DDogs-Lab was captured indoors, featuring various dog breeds trotting on a walkway. It includes data from optical marker-based mocap systems, RGBD cameras, IMUs, and a pressure mat. While providing high-quality motion data, the presence of optical markers and limited background diversity make the captured video less representative of real-world conditions. To address this, we created 3DDogs-Wild, a naturalised version of the dataset where the optical markers are in-painted and the subjects are placed in diverse environments, enhancing its utility for training RGB image-based pose detectors. We show that using the 3DDogs-Wild to train the models leads to improved performance when evaluating on in-the-wild data. Additionally, we provide a thorough analysis using various pose estimation models, revealing their respective strengths and weaknesses. We believe that our findings, coupled with the datasets provided, offer valuable insights for advancing 3D animal pose estimation.
Gaussian Splatting with Localized Points Management
Jun 13, 2024
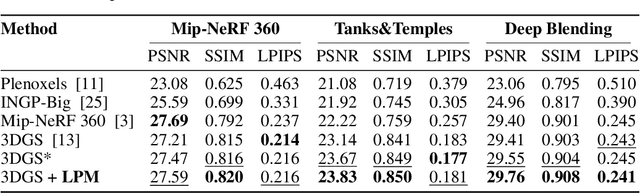
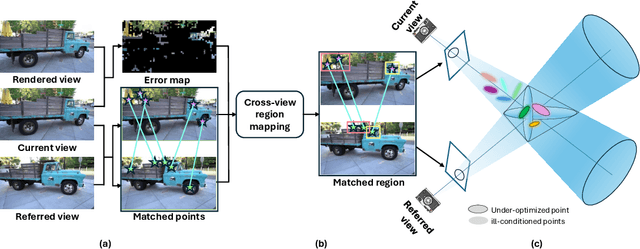

Point management is a critical component in optimizing 3D Gaussian Splatting (3DGS) models, as the point initiation (e.g., via structure from motion) is distributionally inappropriate. Typically, the Adaptive Density Control (ADC) algorithm is applied, leveraging view-averaged gradient magnitude thresholding for point densification, opacity thresholding for pruning, and regular all-points opacity reset. However, we reveal that this strategy is limited in tackling intricate/special image regions (e.g., transparent) as it is unable to identify all the 3D zones that require point densification, and lacking an appropriate mechanism to handle the ill-conditioned points with negative impacts (occlusion due to false high opacity). To address these limitations, we propose a Localized Point Management (LPM) strategy, capable of identifying those error-contributing zones in the highest demand for both point addition and geometry calibration. Zone identification is achieved by leveraging the underlying multiview geometry constraints, with the guidance of image rendering errors. We apply point densification in the identified zone, whilst resetting the opacity of those points residing in front of these regions so that a new opportunity is created to correct ill-conditioned points. Serving as a versatile plugin, LPM can be seamlessly integrated into existing 3D Gaussian Splatting models. Experimental evaluation across both static 3D and dynamic 4D scenes validate the efficacy of our LPM strategy in boosting a variety of existing 3DGS models both quantitatively and qualitatively. Notably, LPM improves both vanilla 3DGS and SpaceTimeGS to achieve state-of-the-art rendering quality while retaining real-time speeds, outperforming on challenging datasets such as Tanks & Temples and the Neural 3D Video Dataset.