 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZSpeedL -- Evaluating the Performance of Zero-Shot Learning Methods using Low-Power Devices
Paper and Code
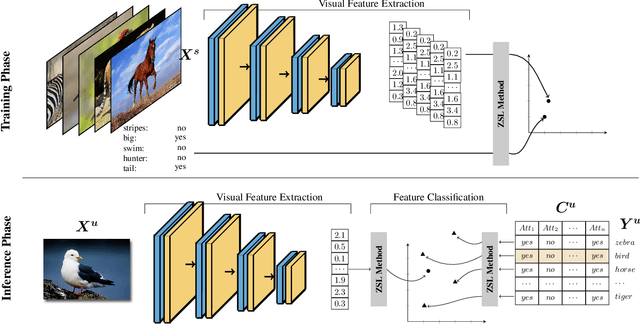
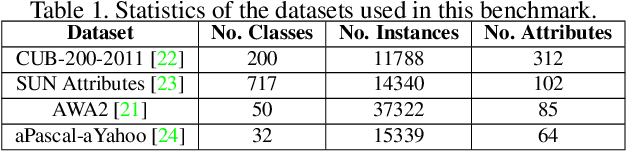

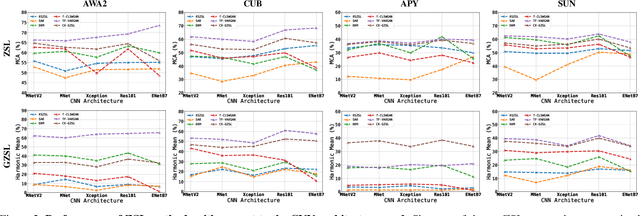
The recognition of unseen objects from a semantic representation or textual description, usually denoted as zero-shot learning, is more prone to be used in real-world scenarios when compared to traditional object recognition. Nevertheless, no work has evaluated the feasibility of deploying zero-shot learning approaches in these scenarios, particularly when using low-power devices. In this paper, we provide the first benchmark on the inference time of zero-shot learning, comprising an evaluation of state-of-the-art approaches regarding their speed/accuracy trade-off. An analysis to the processing time of the different phases of the ZSL inference stage reveals that visual feature extraction is the major bottleneck in this paradigm, but, we show that lightweight networks can dramatically reduce the overall inference time without reducing the accuracy obtained by the de facto ResNet101 architecture. Also, this benchmark evaluates how different ZSL approaches perform in low-power devices, and how the visual feature extraction phase could be optimized in this hardware. To foster the research and deployment of ZSL systems capable of operating in real-world scenarios, we release the evaluation framework used in this benchmark (https://github.com/CristianoPatricio/zsl-methods).