 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Recommendation as Language Modeling
Paper and Code

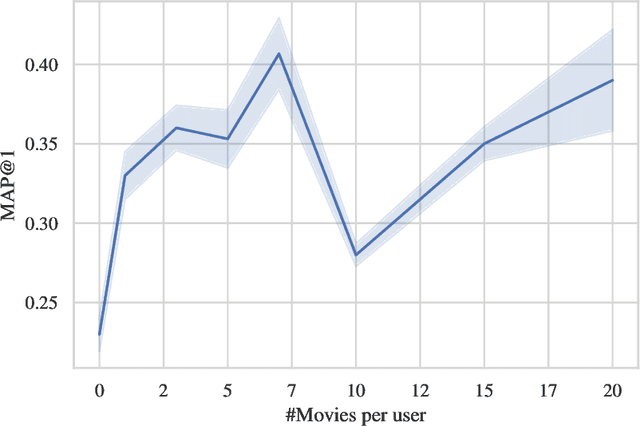
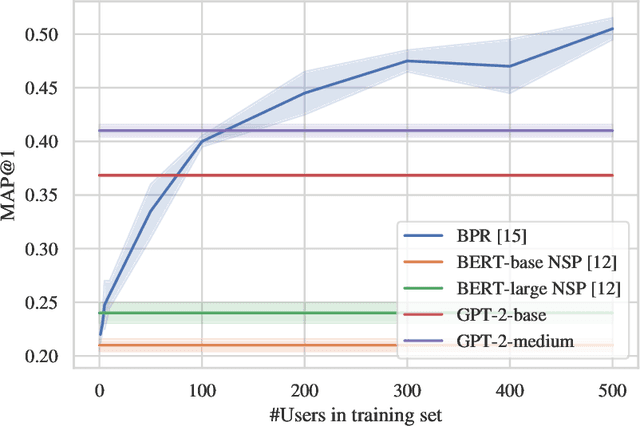
Recommendation is the task of ranking items (e.g. movies or products) according to individual user needs. Current systems rely on collaborative filtering and content-based techniques, which both require structured training data. We propose a framework for recommendation with off-the-shelf pretrained language models (LM) that only used unstructured text corpora as training data. If a user $u$ liked \textit{Matrix} and \textit{Inception}, we construct a textual prompt, e.g. \textit{"Movies like Matrix, Inception, ${<}m{>}$"} to estimate the affinity between $u$ and $m$ with LM likelihood. We motivate our idea with a corpus analysis, evaluate several prompt structures, and we compare LM-based recommendation with standard matrix factorization trained on different data regimes. The code for our experiments is publicly available (https://colab.research.google.com/drive/1f1mlZ-FGaLGdo5rPzxf3vemKllbh2esT?usp=sharing).