 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Assistance in Novel Decision Problems
Paper and Code
Feb 15, 2022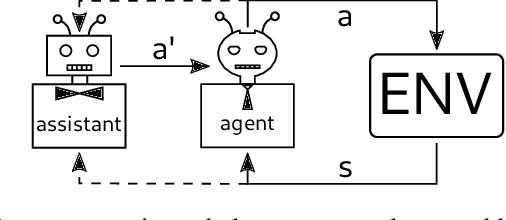
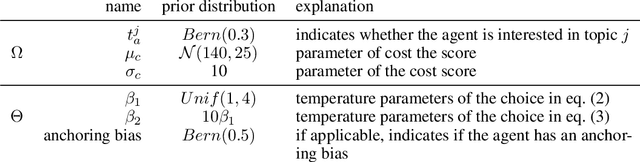

We consider the problem of creating assistants that can help agents - often humans - solve novel sequential decision problems, assuming the agent is not able to specify the reward function explicitly to the assistant. Instead of aiming to automate, and act in place of the agent as in current approaches, we give the assistant an advisory role and keep the agent in the loop as the main decision maker. The difficulty is that we must account for potential biases induced by limitations or constraints of the agent which may cause it to seemingly irrationally reject advice. To do this we introduce a novel formalization of assistance that models these biases, allowing the assistant to infer and adapt to them. We then introduce a new method for planning the assistant's advice which can scale to large decision making problems. Finally, we show experimentally that our approach adapts to these agent biases, and results in higher cumulative reward for the agent than automation-based alternatives.