Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Activity Recognition with Videos
Paper and Code
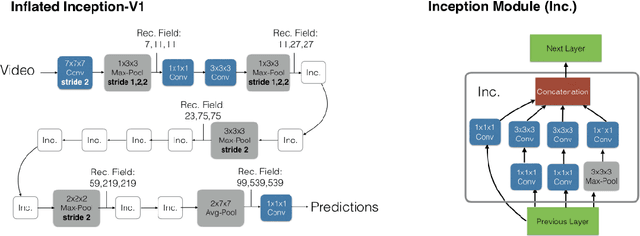
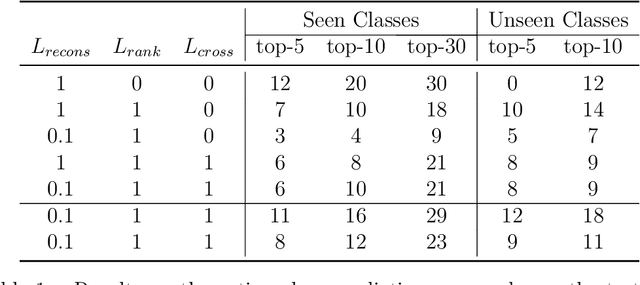
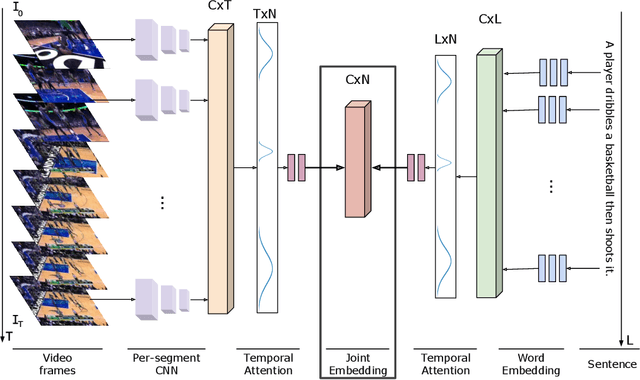
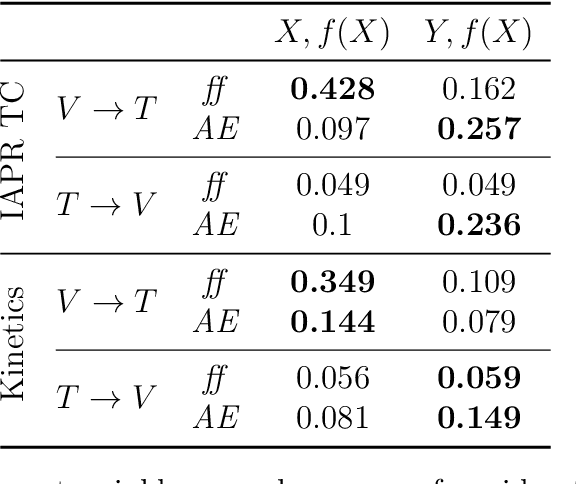
In this paper, we examined the zero-shot activity recognition task with the usage of videos. We introduce an auto-encoder based model to construct a multimodal joint embedding space between the visual and textual manifolds. On the visual side, we used activity videos and a state-of-the-art 3D convolutional action recognition network to extract the features. On the textual side, we worked with GloVe word embeddings. The zero-shot recognition results are evaluated by top-n accuracy. Then, the manifold learning ability is measured by mean Nearest Neighbor Overlap. In the end, we provide an extensive discussion over the results and the future directions.
* This is a research report done during master's studies
View paper on