 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWyner-Ziv Gradient Compression for Federated Learning
Paper and Code
Nov 16, 2021
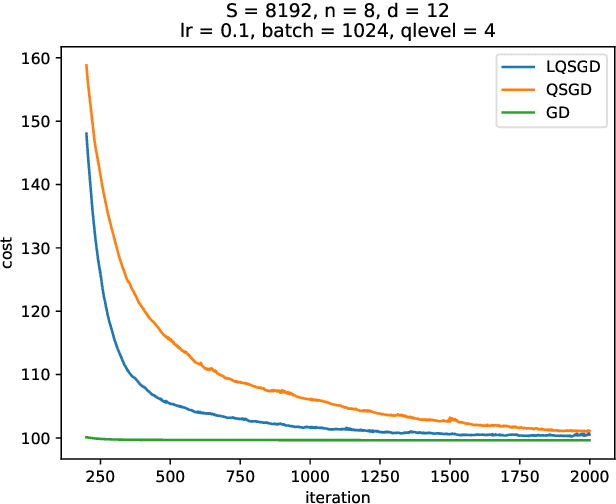
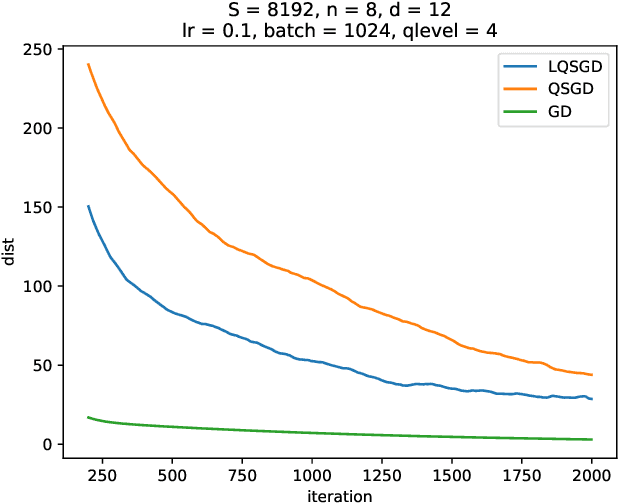
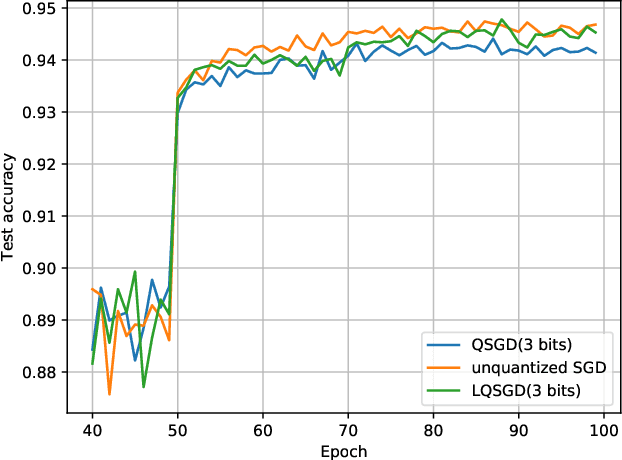
Due to limited communication resources at the client and a massive number of model parameters, large-scale distributed learning tasks suffer from communication bottleneck. Gradient compression is an effective method to reduce communication load by transmitting compressed gradients. Motivated by the fact that in the scenario of stochastic gradients descent, gradients between adjacent rounds may have a high correlation since they wish to learn the same model, this paper proposes a practical gradient compression scheme for federated learning, which uses historical gradients to compress gradients and is based on Wyner-Ziv coding but without any probabilistic assumption. We also implement our gradient quantization method on the real dataset, and the performance of our method is better than the previous schemes.