 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldwide city transport typology prediction with sentence-BERT based supervised learning via Wikipedia
Paper and Code
Mar 29, 2022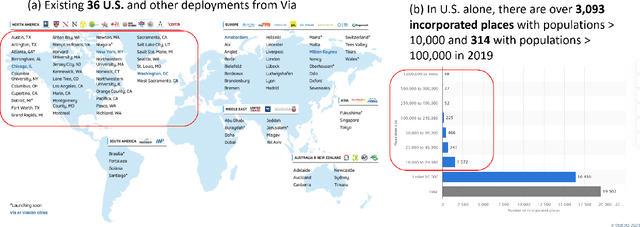

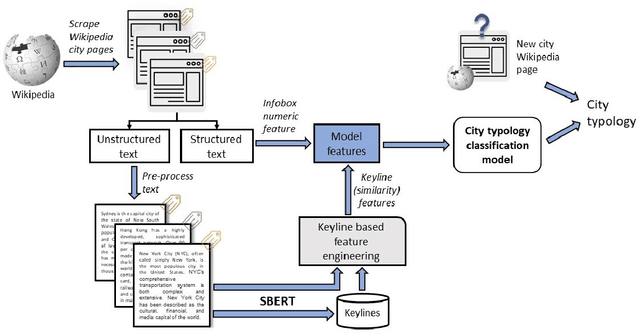
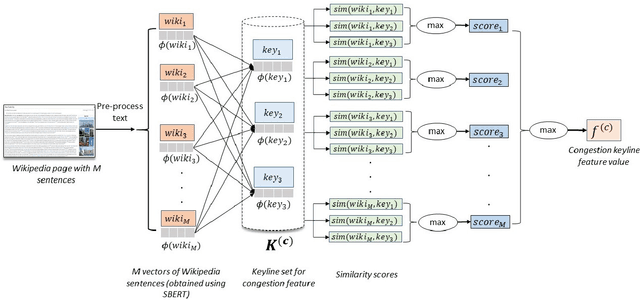
An overwhelming majority of the world's human population lives in urban areas and cities. Understanding a city's transportation typology is immensely valuable for planners and policy makers whose decisions can potentially impact millions of city residents. Despite the value of understanding a city's typology, labeled data (city and it's typology) is scarce, and spans at most a few hundred cities in the current transportation literature. To break this barrier, we propose a supervised machine learning approach to predict a city's typology given the information in its Wikipedia page. Our method leverages recent breakthroughs in natural language processing, namely sentence-BERT, and shows how the text-based information from Wikipedia can be effectively used as a data source for city typology prediction tasks that can be applied to over 2000 cities worldwide. We propose a novel method for low-dimensional city representation using a city's Wikipedia page, which makes supervised learning of city typology labels tractable even with a few hundred labeled samples. These features are used with labeled city samples to train binary classifiers (logistic regression) for four different city typologies: (i) congestion, (ii) auto-heavy, (iii) transit-heavy, and (iv) bike-friendly cities resulting in reasonably high AUC scores of 0.87, 0.86, 0.61 and 0.94 respectively. Our approach provides sufficient flexibility for incorporating additional variables in the city typology models and can be applied to study other city typologies as well. Our findings can assist a diverse group of stakeholders in transportation and urban planning fields, and opens up new opportunities for using text-based information from Wikipedia (or similar platforms) as data sources in such fields.