 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Consistent Video-to-Video Synthesis
Paper and Code
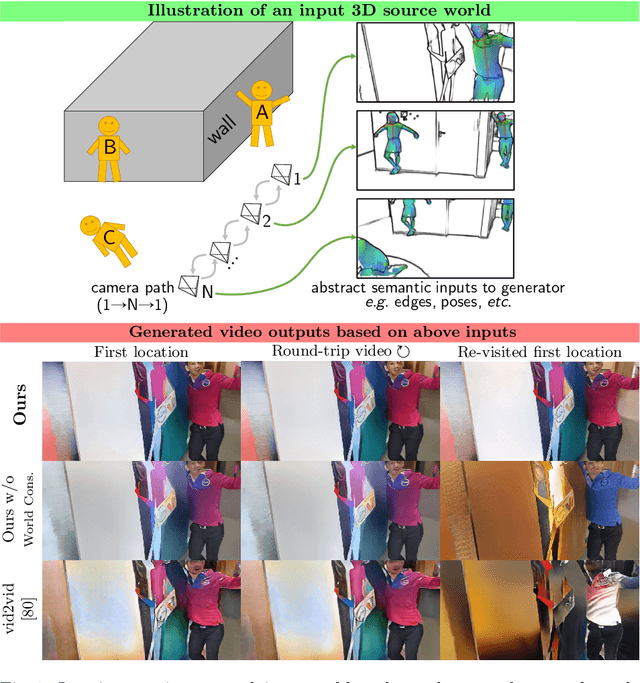

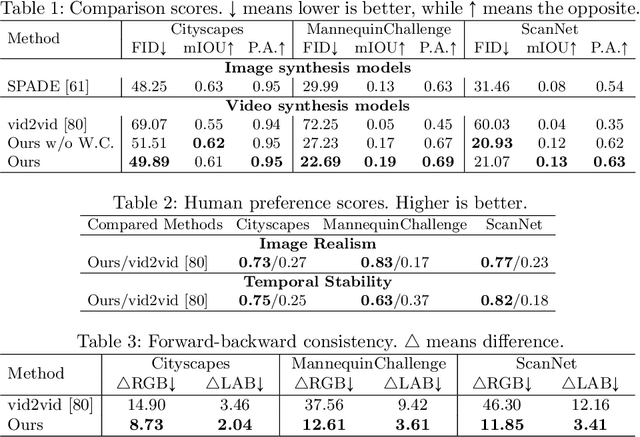
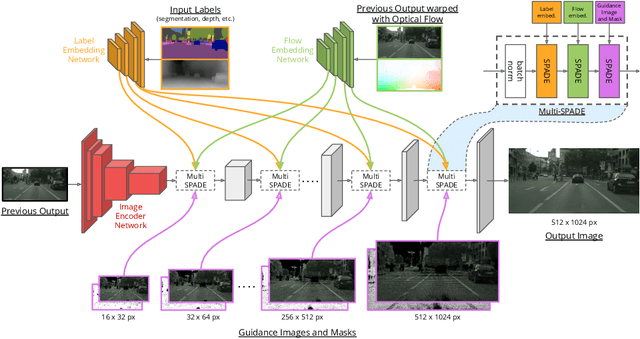
Video-to-video synthesis (vid2vid) aims for converting high-level semantic inputs to photorealistic videos. While existing vid2vid methods can achieve short-term temporal consistency, they fail to ensure the long-term one. This is because they lack knowledge of the 3D world being rendered and generate each frame only based on the past few frames. To address the limitation, we introduce a novel vid2vid framework that efficiently and effectively utilizes all past generated frames during rendering. This is achieved by condensing the 3D world rendered so far into a physically-grounded estimate of the current frame, which we call the guidance image. We further propose a novel neural network architecture to take advantage of the information stored in the guidance images. Extensive experimental results on several challenging datasets verify the effectiveness of our approach in achieving world consistency - the output video is consistent within the entire rendered 3D world. https://nvlabs.github.io/wc-vid2vid/