Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord to Sentence Visual Semantic Similarity for Caption Generation: Lessons Learned
Paper and Code


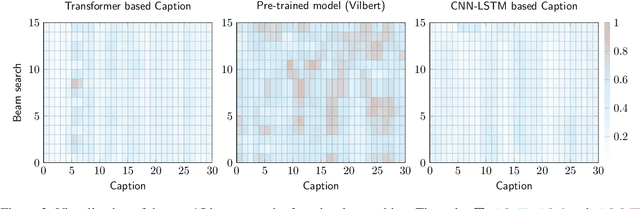

This paper focuses on enhancing the captions generated by image-caption generation systems. We propose an approach for improving caption generation systems by choosing the most closely related output to the image rather than the most likely output produced by the model. Our model revises the language generation output beam search from a visual context perspective. We employ a visual semantic measure in a word and sentence level manner to match the proper caption to the related information in the image. The proposed approach can be applied to any caption system as a post-processing based method.
* Technical Report (published 27 March 2022)
View paper on