 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Embedding Algorithms as Generalized Low Rank Models and their Canonical Form
Paper and Code
Nov 06, 2019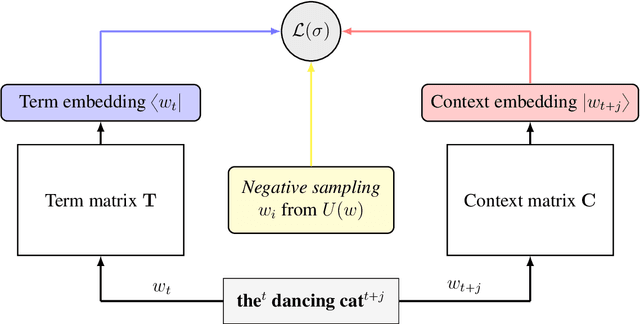

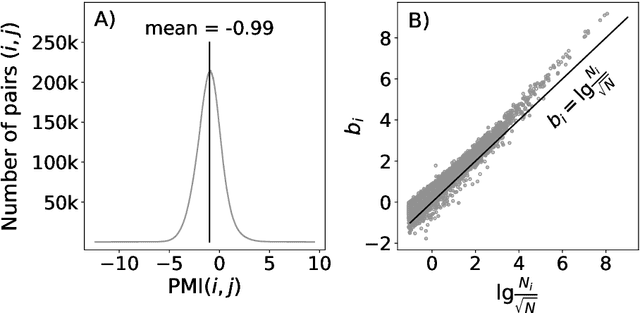

Word embedding algorithms produce very reliable feature representations of words that are used by neural network models across a constantly growing multitude of NLP tasks. As such, it is imperative for NLP practitioners to understand how their word representations are produced, and why they are so impactful. The present work presents the Simple Embedder framework, generalizing the state-of-the-art existing word embedding algorithms (including Word2vec (SGNS) and GloVe) under the umbrella of generalized low rank models. We derive that both of these algorithms attempt to produce embedding inner products that approximate pointwise mutual information (PMI) statistics in the corpus. Once cast as Simple Embedders, comparison of these models reveals that these successful embedders all resemble a straightforward maximum likelihood estimate (MLE) of the PMI parametrized by the inner product (between embeddings). This MLE induces our proposed novel word embedding model, Hilbert-MLE, as the canonical representative of the Simple Embedder framework. We empirically compare these algorithms with evaluations on 17 different datasets. Hilbert-MLE consistently observes second-best performance on every extrinsic evaluation (news classification, sentiment analysis, POS-tagging, and supersense tagging), while the first-best model depends varying on the task. Moreover, Hilbert-MLE consistently observes the least variance in results with respect to the random initialization of the weights in bidirectional LSTMs. Our empirical results demonstrate that Hilbert-MLE is a very consistent word embedding algorithm that can be reliably integrated into existing NLP systems to obtain high-quality results.