 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Existing Multimodal Crowd Counting Datasets Can Lead to Unfulfilled Expectations in Real-World Applications
Paper and Code
Apr 13, 2023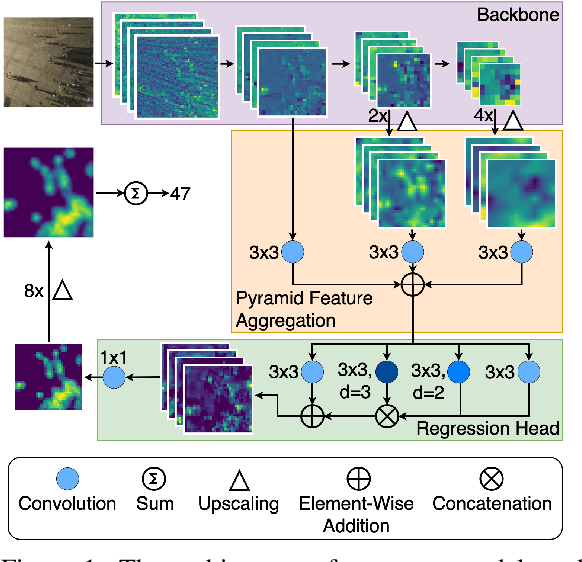
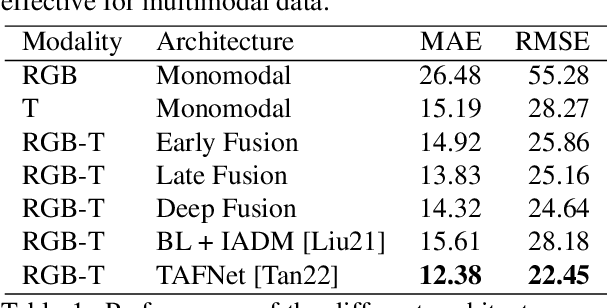
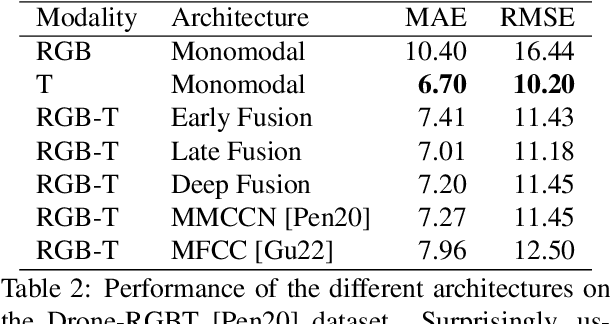

More information leads to better decisions and predictions, right? Confirming this hypothesis, several studies concluded that the simultaneous use of optical and thermal images leads to better predictions in crowd counting. However, the way multimodal models extract enriched features from both modalities is not yet fully understood. Since the use of multimodal data usually increases the complexity, inference time, and memory requirements of the models, it is relevant to examine the differences and advantages of multimodal compared to monomodal models. In this work, all available multimodal datasets for crowd counting are used to investigate the differences between monomodal and multimodal models. To do so, we designed a monomodal architecture that considers the current state of research on monomodal crowd counting. In addition, several multimodal architectures have been developed using different multimodal learning strategies. The key components of the monomodal architecture are also used in the multimodal architectures to be able to answer whether multimodal models perform better in crowd counting in general. Surprisingly, no general answer to this question can be derived from the existing datasets. We found that the existing datasets hold a bias toward thermal images. This was determined by analyzing the relationship between the brightness of optical images and crowd count as well as examining the annotations made for each dataset. Since answering this question is important for future real-world applications of crowd counting, this paper establishes criteria for a potential dataset suitable for answering whether multimodal models perform better in crowd counting in general.