 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk-and-Relate: A Random-Walk-based Algorithm for Representation Learning on Sparse Knowledge Graphs
Paper and Code

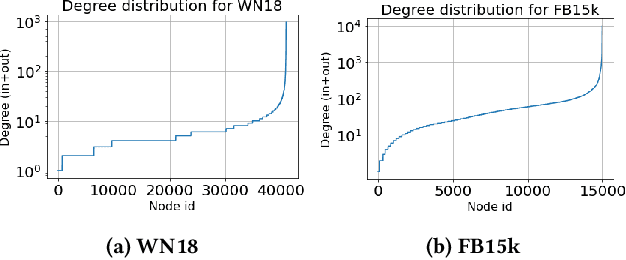

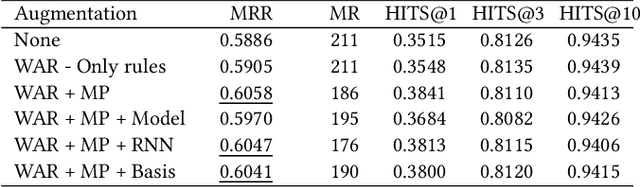
Knowledge graph (KG) embedding techniques use structured relationships between entities to learn low-dimensional representations of entities and relations. The traditional KG embedding techniques (such as TransE and DistMult) estimate these embeddings via simple models developed over observed KG triplets. These approaches differ in their triplet scoring loss functions. As these models only use the observed triplets to estimate the embeddings, they are prone to suffer through data sparsity that usually occurs in the real-world knowledge graphs, i.e., the lack of enough triplets per entity. To settle this issue, we propose an efficient method to augment the number of triplets to address the problem of data sparsity. We use random walks to create additional triplets, such that the relations carried by these introduced triplets entail the metapath induced by the random walks. We also provide approaches to accurately and efficiently filter out informative metapaths from the possible set of metapaths, induced by the random walks. The proposed approaches are model-agnostic, and the augmented training dataset can be used with any KG embedding approach out of the box. Experimental results obtained on the benchmark datasets show the advantages of the proposed approach.