 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaDeNet: Wavelet Decomposition based CNN for Speech Processing
Paper and Code
Nov 11, 2020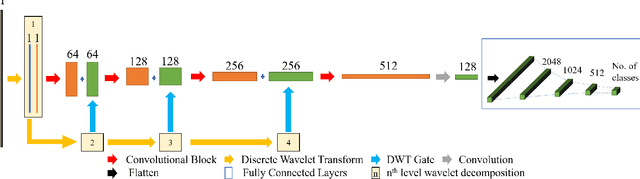
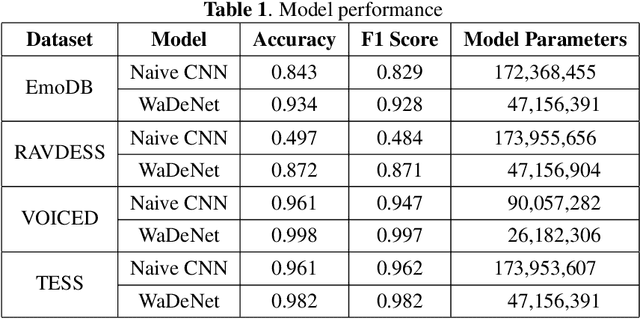
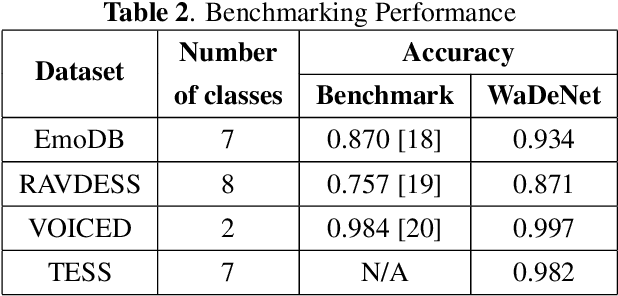
Existing speech processing systems consist of different modules, individually optimized for a specific task such as acoustic modelling or feature extraction. In addition to not assuring optimality of the system, the disjoint nature of current speech processing systems make them unsuitable for ubiquitous health applications. We propose WaDeNet, an end-to-end model for mobile speech processing. In order to incorporate spectral features, WaDeNet embeds wavelet decomposition of the speech signal within the architecture. This allows WaDeNet to learn from spectral features in an end-to-end manner, thus alleviating the need for feature extraction and successive modules that are currently present in speech processing systems. WaDeNet outperforms the current state of the art in datasets that involve speech for mobile health applications such as non-invasive emotion recognition. WaDeNet achieves an average increase in accuracy of 6.36% when compared to the existing state of the art models. Additionally, WaDeNet is considerably lighter than a simple CNNs with a similar architecture.