 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Conversion Based Speaker Normalization for Acoustic Unit Discovery
Paper and Code
May 04, 2021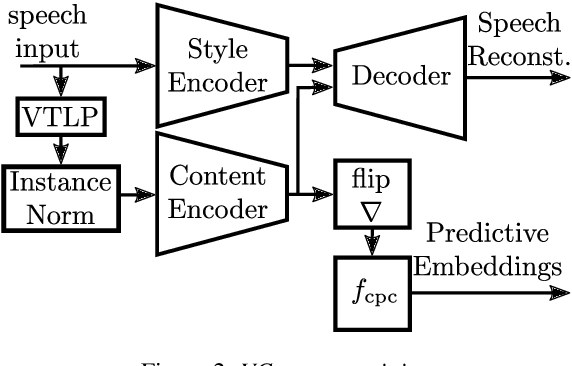
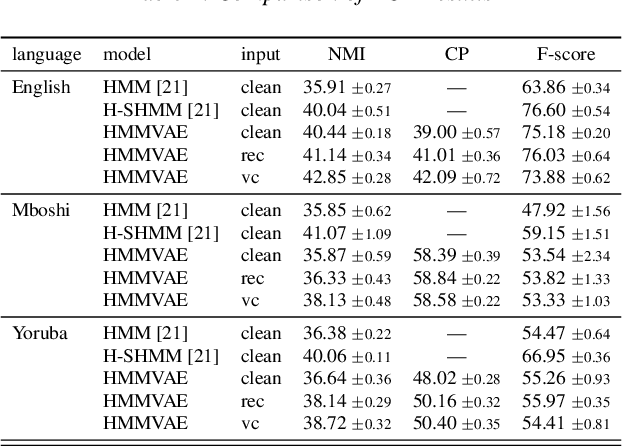
Discovering speaker independent acoustic units purely from spoken input is known to be a hard problem. In this work we propose an unsupervised speaker normalization technique prior to unit discovery. It is based on separating speaker related from content induced variations in a speech signal with an adversarial contrastive predictive coding approach. This technique does neither require transcribed speech nor speaker labels, and, furthermore, can be trained in a multilingual fashion, thus achieving speaker normalization even if only few unlabeled data is available from the target language. The speaker normalization is done by mapping all utterances to a medoid style which is representative for the whole database. We demonstrate the effectiveness of the approach by conducting acoustic unit discovery with a hidden Markov model variational autoencoder noting, however, that the proposed speaker normalization can serve as a front end to any unit discovery system. Experiments on English, Yoruba and Mboshi show improvements compared to using non-normalized input.