 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-Linearizer: Distilling Quadratic Knowledge into Linear-Time Vision Models
Paper and Code
Mar 30, 2025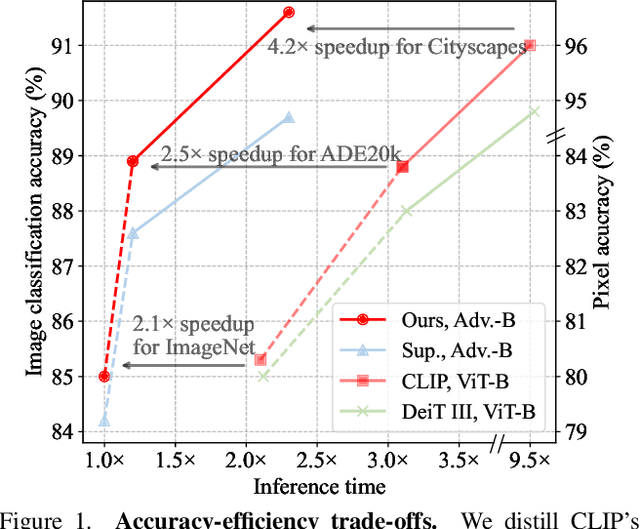

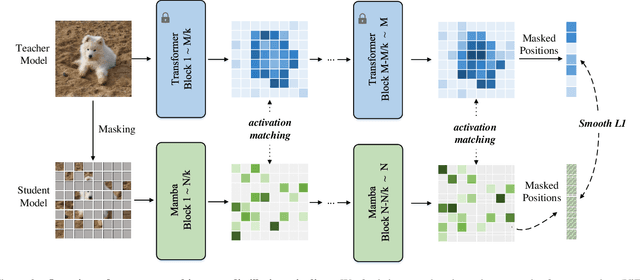

Vision Transformers (ViTs) have delivered remarkable progress through global self-attention, yet their quadratic complexity can become prohibitive for high-resolution inputs. In this work, we present ViT-Linearizer, a cross-architecture distillation framework that transfers rich ViT representations into a linear-time, recurrent-style model. Our approach leverages 1) activation matching, an intermediate constraint that encourages student to align its token-wise dependencies with those produced by the teacher, and 2) masked prediction, a contextual reconstruction objective that requires the student to predict the teacher's representations for unseen (masked) tokens, to effectively distill the quadratic self-attention knowledge into the student while maintaining efficient complexity. Empirically, our method provides notable speedups particularly for high-resolution tasks, significantly addressing the hardware challenges in inference. Additionally, it also elevates Mamba-based architectures' performance on standard vision benchmarks, achieving a competitive 84.3% top-1 accuracy on ImageNet with a base-sized model. Our results underscore the good potential of RNN-based solutions for large-scale visual tasks, bridging the gap between theoretical efficiency and real-world practice.