 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT Cane: Visual Assistant for the Visually Impaired
Paper and Code
Sep 26, 2021
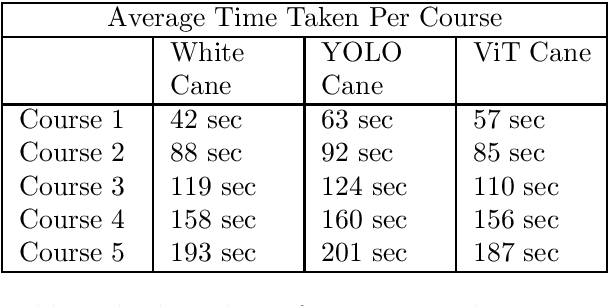
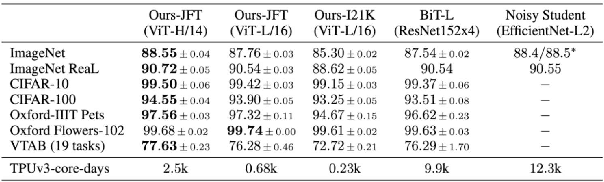
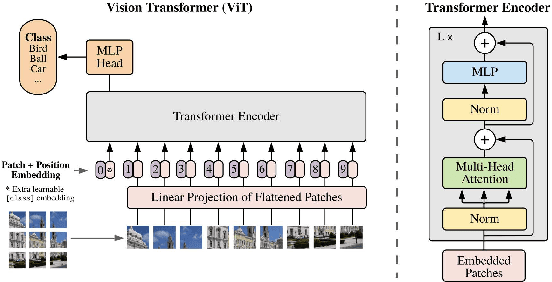
Blind and visually challenged face multiple issues with navigating the world independently. Some of these challenges include finding the shortest path to a destination and detecting obstacles from a distance. To tackle this issue, this paper proposes ViT Cane, which leverages a vision transformer model in order to detect obstacles in real-time. Our entire system consists of a Pi Camera Module v2, Raspberry Pi 4B with 8GB Ram and 4 motors. Based on tactile input using the 4 motors, the obstacle detection model is highly efficient in helping visually impaired navigate unknown terrain and is designed to be easily reproduced. The paper discusses the utility of a Visual Transformer model in comparison to other CNN based models for this specific application. Through rigorous testing, the proposed obstacle detection model has achieved higher performance on the Common Object in Context (COCO) data set than its CNN counterpart. Comprehensive field tests were conducted to verify the effectiveness of our system for holistic indoor understanding and obstacle avoidance.