 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Depth Mapping from Monocular Images using Recurrent Convolutional Neural Networks
Paper and Code
Dec 10, 2018


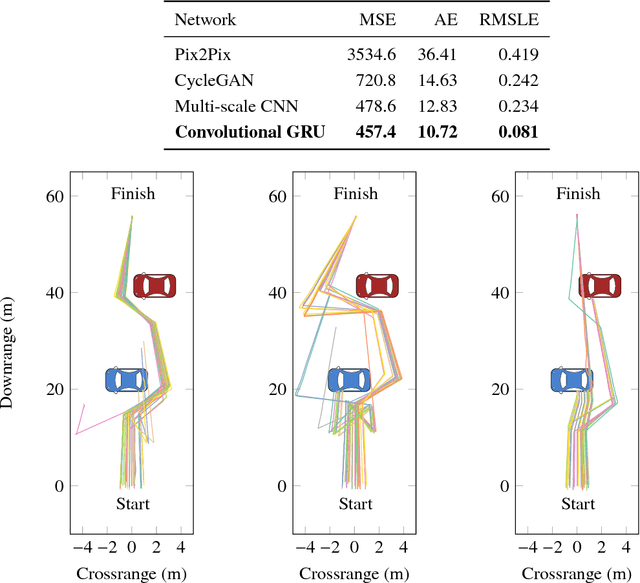
A reliable sense-and-avoid system is critical to enabling safe autonomous operation of unmanned aircraft. Existing sense-and-avoid methods often require specialized sensors that are too large or power intensive for use on small unmanned vehicles. This paper presents a method to estimate object distances based on visual image sequences, allowing for the use of low-cost, on-board monocular cameras as simple collision avoidance sensors. We present a deep recurrent convolutional neural network and training method to generate depth maps from video sequences. Our network is trained using simulated camera and depth data generated with Microsoft's AirSim simulator. Empirically, we show that our model achieves superior performance compared to models generated using prior methods.We further demonstrate that the method can be used for sense-and-avoid of obstacles in simulation.