 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Environmental Perception for Autonomous Driving
Paper and Code
Dec 22, 2022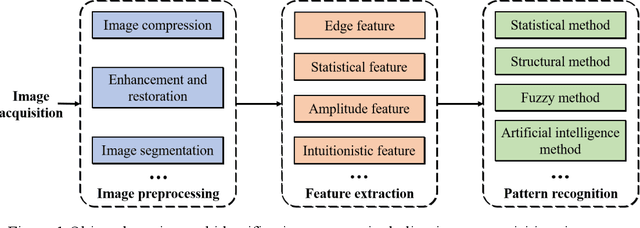
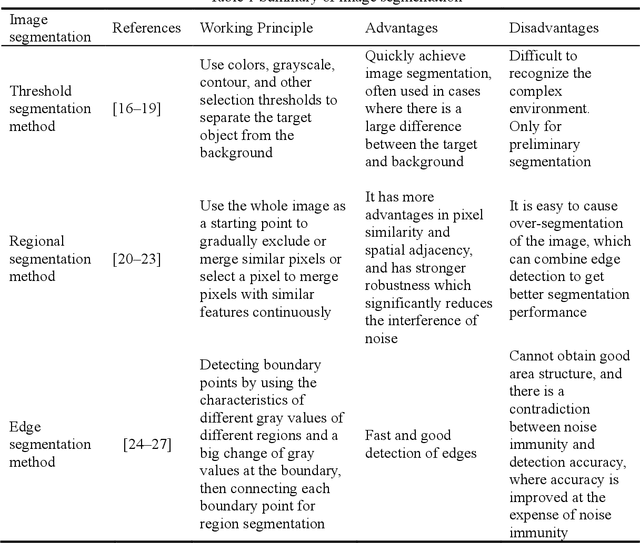


Visual perception plays an important role in autonomous driving. One of the primary tasks is object detection and identification. Since the vision sensor is rich in color and texture information, it can quickly and accurately identify various road information. The commonly used technique is based on extracting and calculating various features of the image. The recent development of deep learning-based method has better reliability and processing speed and has a greater advantage in recognizing complex elements. For depth estimation, vision sensor is also used for ranging due to their small size and low cost. Monocular camera uses image data from a single viewpoint as input to estimate object depth. In contrast, stereo vision is based on parallax and matching feature points of different views, and the application of deep learning also further improves the accuracy. In addition, Simultaneous Location and Mapping (SLAM) can establish a model of the road environment, thus helping the vehicle perceive the surrounding environment and complete the tasks. In this paper, we introduce and compare various methods of object detection and identification, then explain the development of depth estimation and compare various methods based on monocular, stereo, and RDBG sensors, next review and compare various methods of SLAM, and finally summarize the current problems and present the future development trends of vision technologies.