 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Based Moving K-Means Algorithm
Paper and Code
May 12, 2017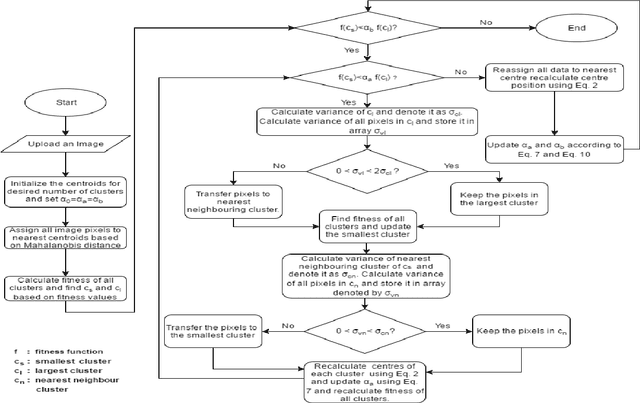
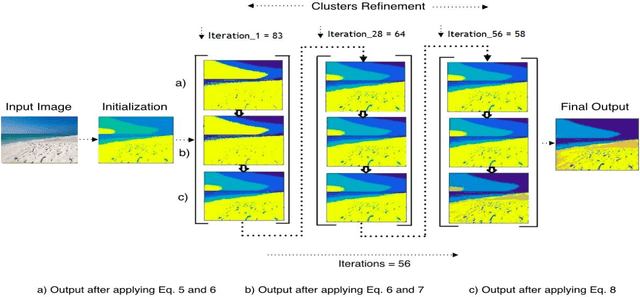
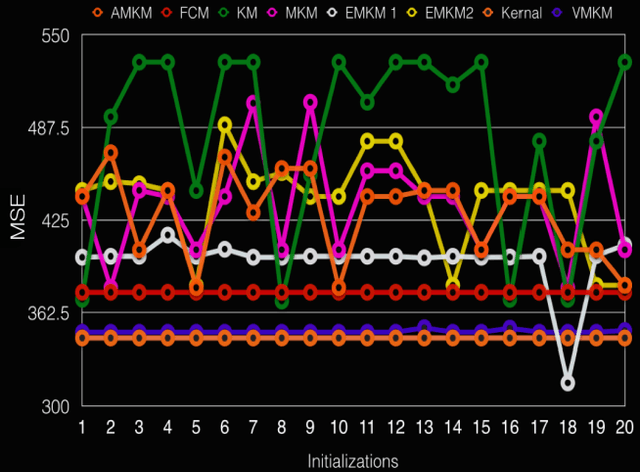

Clustering is a useful data exploratory method with its wide applicability in multiple fields. However, data clustering greatly relies on initialization of cluster centers that can result in large intra-cluster variance and dead centers, therefore leading to sub-optimal solutions. This paper proposes a novel variance based version of the conventional Moving K-Means (MKM) algorithm called Variance Based Moving K-Means (VMKM) that can partition data into optimal homogeneous clusters, irrespective of cluster initialization. The algorithm utilizes a novel distance metric and a unique data element selection criteria to transfer the selected elements between clusters to achieve low intra-cluster variance and subsequently avoid dead centers. Quantitative and qualitative comparison with various clustering techniques is performed on four datasets selected from image processing, bioinformatics, remote sensing and the stock market respectively. An extensive analysis highlights the superior performance of the proposed method over other techniques.