 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse and Misuse of Machine Learning in Anthropology
Paper and Code
Sep 06, 2022
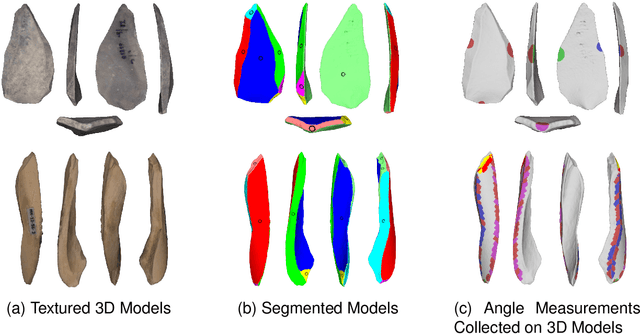
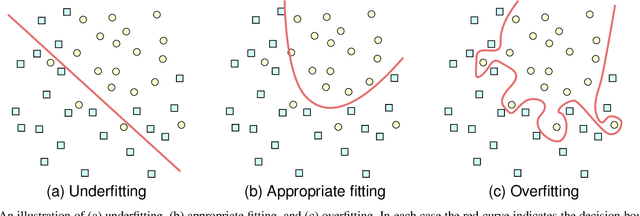
Machine learning (ML), being now widely accessible to the research community at large, has fostered a proliferation of new and striking applications of these emergent mathematical techniques across a wide range of disciplines. In this paper, we will focus on a particular case study: the field of paleoanthropology, which seeks to understand the evolution of the human species based on biological and cultural evidence. As we will show, the easy availability of ML algorithms and lack of expertise on their proper use among the anthropological research community has led to foundational misapplications that have appeared throughout the literature. The resulting unreliable results not only undermine efforts to legitimately incorporate ML into anthropological research, but produce potentially faulty understandings about our human evolutionary and behavioral past. The aim of this paper is to provide a brief introduction to some of the ways in which ML has been applied within paleoanthropology; we also include a survey of some basic ML algorithms for those who are not fully conversant with the field, which remains under active development. We discuss a series of missteps, errors, and violations of correct protocols of ML methods that appear disconcertingly often within the accumulating body of anthropological literature. These mistakes include use of outdated algorithms and practices; inappropriate train/test splits, sample composition, and textual explanations; as well as an absence of transparency due to the lack of data/code sharing, and the subsequent limitations imposed on independent replication. We assert that expanding samples, sharing data and code, re-evaluating approaches to peer review, and, most importantly, developing interdisciplinary teams that include experts in ML are all necessary for progress in future research incorporating ML within anthropology.