 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Tokenization Learning
Paper and Code
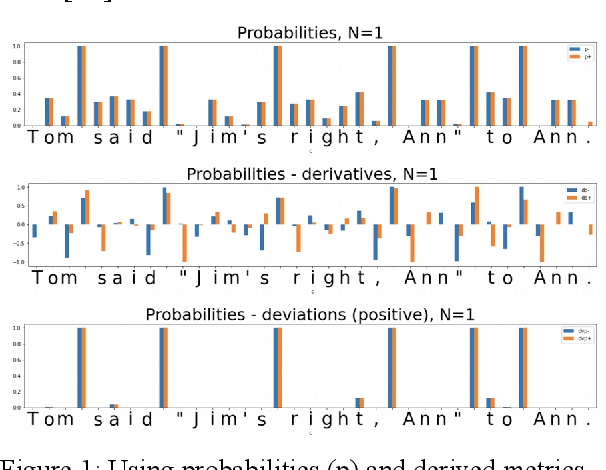
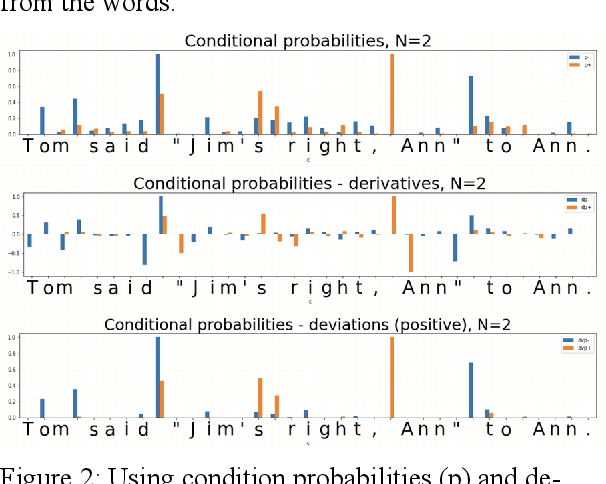
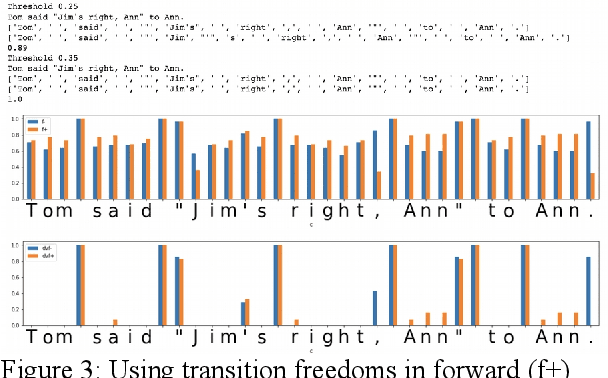
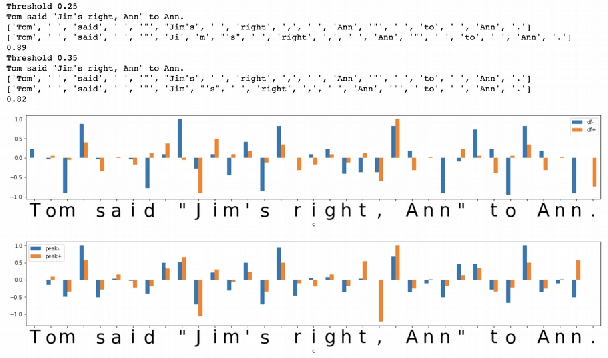
In the presented study, we discover that so called "transition freedom" metric appears superior for unsupervised tokenization purposes, compared to statistical metrics such as mutual information and conditional probability, providing F-measure scores in range from 0.71 to 1.0 across explored corpora. We find that different languages require different derivatives of that metric (such as variance and "peak values") for successful tokenization. Larger training corpora does not necessarily effect in better tokenization quality, while compacting the models eliminating statistically weak evidence tends to improve performance. Proposed unsupervised tokenization technique provides quality better or comparable to lexicon-based one, depending on the language.