 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Distributional Properties can Supplement Human Labeling and Increase Active Learning Efficiency in Anomaly Detection
Paper and Code
Jul 13, 2023

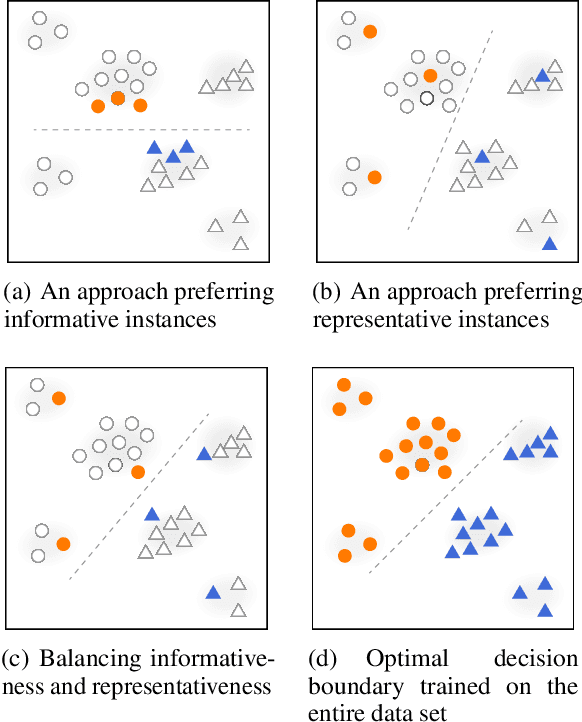

Exfiltration of data via email is a serious cybersecurity threat for many organizations. Detecting data exfiltration (anomaly) patterns typically requires labeling, most often done by a human annotator, to reduce the high number of false alarms. Active Learning (AL) is a promising approach for labeling data efficiently, but it needs to choose an efficient order in which cases are to be labeled, and there are uncertainties as to what scoring procedure should be used to prioritize cases for labeling, especially when detecting rare cases of interest is crucial. We propose an adaptive AL sampling strategy that leverages the underlying prior data distribution, as well as model uncertainty, to produce batches of cases to be labeled that contain instances of rare anomalies. We show that (1) the classifier benefits from a batch of representative and informative instances of both normal and anomalous examples, (2) unsupervised anomaly detection plays a useful role in building the classifier in the early stages of training when relatively little labeling has been done thus far. Our approach to AL for anomaly detection outperformed existing AL approaches on three highly unbalanced UCI benchmarks and on one real-world redacted email data set.