 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Ensemble Ranking of Terms in Electronic Health Record Notes Based on Their Importance to Patients
Paper and Code
Mar 25, 2017
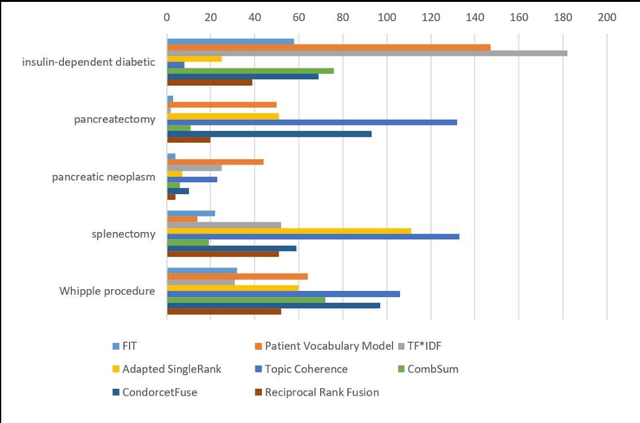
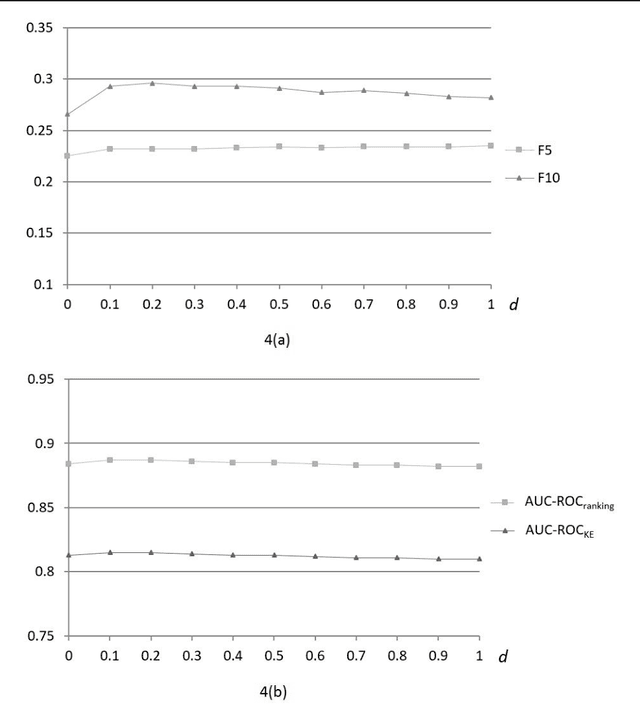
Background: Electronic health record (EHR) notes contain abundant medical jargon that can be difficult for patients to comprehend. One way to help patients is to reduce information overload and help them focus on medical terms that matter most to them. Objective: The aim of this work was to develop FIT (Finding Important Terms for patients), an unsupervised natural language processing (NLP) system that ranks medical terms in EHR notes based on their importance to patients. Methods: We built FIT on a new unsupervised ensemble ranking model derived from the biased random walk algorithm to combine heterogeneous information resources for ranking candidate terms from each EHR note. Specifically, FIT integrates four single views for term importance: patient use of medical concepts, document-level term salience, word-occurrence based term relatedness, and topic coherence. It also incorporates partial information of term importance as conveyed by terms' unfamiliarity levels and semantic types. We evaluated FIT on 90 expert-annotated EHR notes and compared it with three benchmark unsupervised ensemble ranking methods. Results: FIT achieved 0.885 AUC-ROC for ranking candidate terms from EHR notes to identify important terms. When including term identification, the performance of FIT for identifying important terms from EHR notes was 0.813 AUC-ROC. It outperformed the three ensemble rankers for most metrics. Its performance is relatively insensitive to its parameter. Conclusions: FIT can automatically identify EHR terms important to patients and may help develop personalized interventions to improve quality of care. By using unsupervised learning as well as a robust and flexible framework for information fusion, FIT can be readily applied to other domains and applications.