 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Model Insights: A Dataset for Automated Model Card Generation
Paper and Code
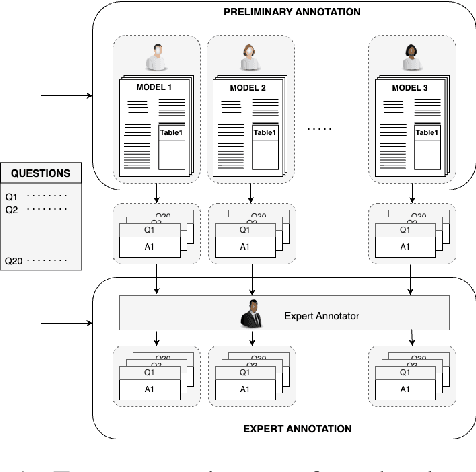



Language models (LMs) are no longer restricted to ML community, and instruction-tuned LMs have led to a rise in autonomous AI agents. As the accessibility of LMs grows, it is imperative that an understanding of their capabilities, intended usage, and development cycle also improves. Model cards are a popular practice for documenting detailed information about an ML model. To automate model card generation, we introduce a dataset of 500 question-answer pairs for 25 ML models that cover crucial aspects of the model, such as its training configurations, datasets, biases, architecture details, and training resources. We employ annotators to extract the answers from the original paper. Further, we explore the capabilities of LMs in generating model cards by answering questions. Our initial experiments with ChatGPT-3.5, LLaMa, and Galactica showcase a significant gap in the understanding of research papers by these aforementioned LMs as well as generating factual textual responses. We posit that our dataset can be used to train models to automate the generation of model cards from paper text and reduce human effort in the model card curation process. The complete dataset is available on https://osf.io/hqt7p/?view_only=3b9114e3904c4443bcd9f5c270158d37