 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMat: Unifying Materials Embeddings through Multi-modal Learning
Paper and Code
Nov 13, 2024
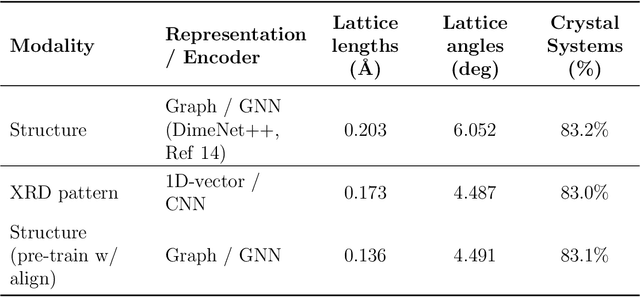
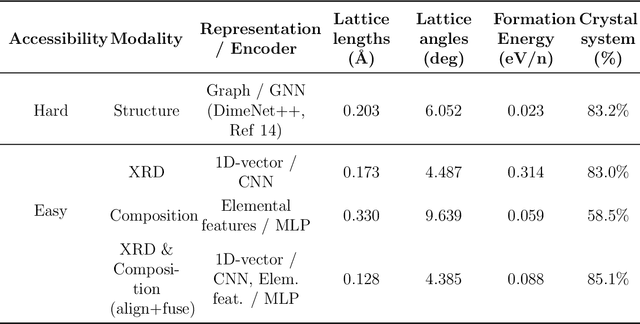

Materials science datasets are inherently heterogeneous and are available in different modalities such as characterization spectra, atomic structures, microscopic images, and text-based synthesis conditions. The advancements in multi-modal learning, particularly in vision and language models, have opened new avenues for integrating data in different forms. In this work, we evaluate common techniques in multi-modal learning (alignment and fusion) in unifying some of the most important modalities in materials science: atomic structure, X-ray diffraction patterns (XRD), and composition. We show that structure graph modality can be enhanced by aligning with XRD patterns. Additionally, we show that aligning and fusing more experimentally accessible data formats, such as XRD patterns and compositions, can create more robust joint embeddings than individual modalities across various tasks. This lays the groundwork for future studies aiming to exploit the full potential of multi-modal data in materials science, facilitating more informed decision-making in materials design and discovery.