 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Transfer Learning for Chest Radiograph Clinical Report Generation with Modified Transformer Architectures
Paper and Code
May 05, 2022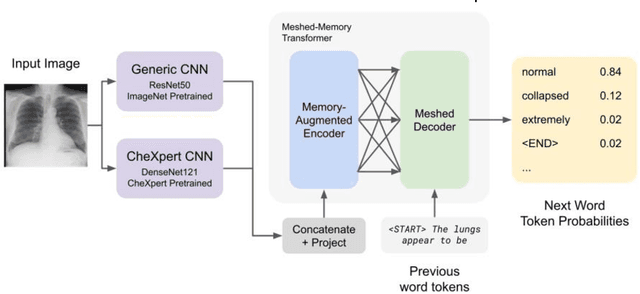



The image captioning task is increasingly prevalent in artificial intelligence applications for medicine. One important application is clinical report generation from chest radiographs. The clinical writing of unstructured reports is time consuming and error-prone. An automated system would improve standardization, error reduction, time consumption, and medical accessibility. In this paper we demonstrate the importance of domain specific pre-training and propose a modified transformer architecture for the medical image captioning task. To accomplish this, we train a series of modified transformers to generate clinical reports from chest radiograph image input. These modified transformers include: a meshed-memory augmented transformer architecture with visual extractor using ImageNet pre-trained weights, a meshed-memory augmented transformer architecture with visual extractor using CheXpert pre-trained weights, and a meshed-memory augmented transformer whose encoder is passed the concatenated embeddings using both ImageNet pre-trained weights and CheXpert pre-trained weights. We use BLEU(1-4), ROUGE-L, CIDEr, and the clinical CheXbert F1 scores to validate our models and demonstrate competitive scores with state of the art models. We provide evidence that ImageNet pre-training is ill-suited for the medical image captioning task, especially for less frequent conditions (eg: enlarged cardiomediastinum, lung lesion, pneumothorax). Furthermore, we demonstrate that the double feature model improves performance for specific medical conditions (edema, consolidation, pneumothorax, support devices) and overall CheXbert F1 score, and should be further developed in future work. Such a double feature model, including both ImageNet pre-training as well as domain specific pre-training, could be used in a wide range of image captioning models in medicine.