 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Pre-Editing for Black-Box Neural Machine Translation
Paper and Code

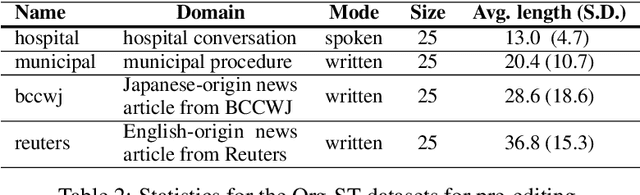
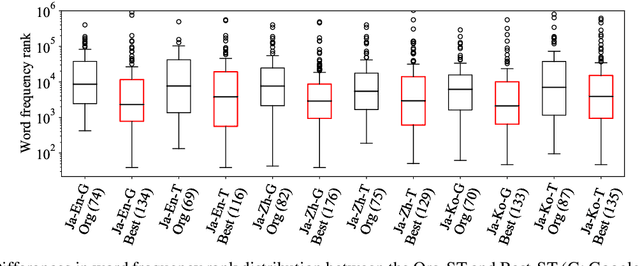
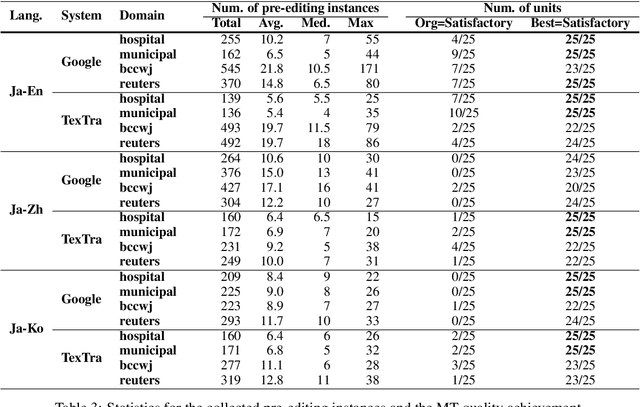
Pre-editing is the process of modifying the source text (ST) so that it can be translated by machine translation (MT) in a better quality. Despite the unpredictability of black-box neural MT (NMT), pre-editing has been deployed in various practical MT use cases. Although many studies have demonstrated the effectiveness of pre-editing methods for particular settings, thus far, a deep understanding of what pre-editing is and how it works for black-box NMT is lacking. To elicit such understanding, we extensively investigated human pre-editing practices. We first implemented a protocol to incrementally record the minimum edits for each ST and collected 6,652 instances of pre-editing across three translation directions, two MT systems, and four text domains. We then analysed the instances from three perspectives: the characteristics of the pre-edited ST, the diversity of pre-editing operations, and the impact of the pre-editing operations on NMT outputs. Our findings include the following: (1) enhancing the explicitness of the meaning of an ST and its syntactic structure is more important for obtaining better translations than making the ST shorter and simpler, and (2) although the impact of pre-editing on NMT is generally unpredictable, there are some tendencies of changes in the NMT outputs depending on the editing operation types.