 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Approximation for Bayesian Inference in Neural Networks
Paper and Code



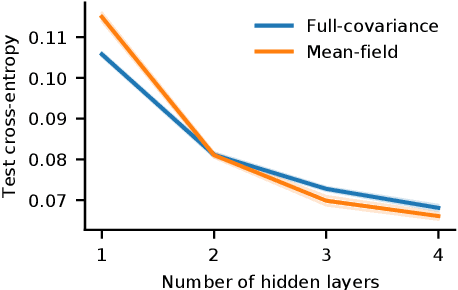
Bayesian inference has theoretical attractions as a principled framework for reasoning about beliefs. However, the motivations of Bayesian inference which claim it to be the only 'rational' kind of reasoning do not apply in practice. They create a binary split in which all approximate inference is equally 'irrational'. Instead, we should ask ourselves how to define a spectrum of more- and less-rational reasoning that explains why we might prefer one Bayesian approximation to another. I explore approximate inference in Bayesian neural networks and consider the unintended interactions between the probabilistic model, approximating distribution, optimization algorithm, and dataset. The complexity of these interactions highlights the difficulty of any strategy for evaluating Bayesian approximations which focuses entirely on the method, outside the context of specific datasets and decision-problems. For given applications, the expected utility of the approximate posterior can measure inference quality. To assess a model's ability to incorporate different parts of the Bayesian framework we can identify desirable characteristic behaviours of Bayesian reasoning and pick decision-problems that make heavy use of those behaviours. Here, we use continual learning (testing the ability to update sequentially) and active learning (testing the ability to represent credence). But existing continual and active learning set-ups pose challenges that have nothing to do with posterior quality which can distort their ability to evaluate Bayesian approximations. These unrelated challenges can be removed or reduced, allowing better evaluation of approximate inference methods.