 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification in Machine Learning for Joint Speaker Diarization and Identification
Paper and Code
Dec 30, 2023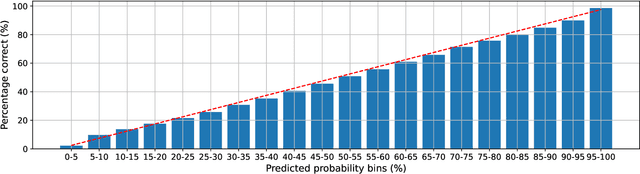
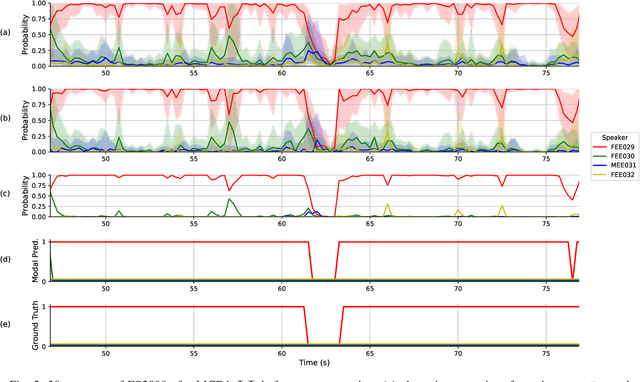
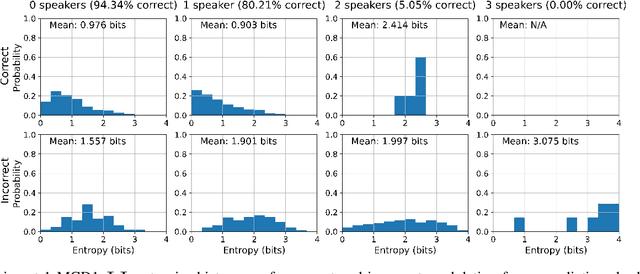
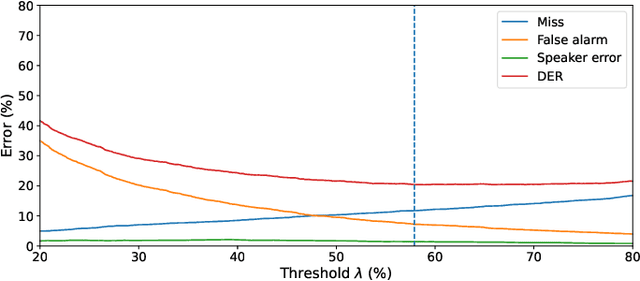
This paper studies modulation spectrum features ($\Phi$) and mel-frequency cepstral coefficients ($\Psi$) in joint speaker diarization and identification (JSID). JSID is important as speaker diarization on its own to distinguish speakers is insufficient for many applications, it is often necessary to identify speakers as well. Machine learning models are set up using convolutional neural networks (CNNs) on $\Phi$ and recurrent neural networks $\unicode{x2013}$ long short-term memory (LSTMs) on $\Psi$, then concatenating into fully connected layers. Experiment 1 shows models on both $\Phi$ and $\Psi$ have better diarization error rates (DERs) than models on either alone; a CNN on $\Phi$ has DER 29.09\%, compared to 27.78\% for a LSTM on $\Psi$ and 19.44\% for a model on both. Experiment 1 also investigates aleatoric uncertainties and shows the model on both $\Phi$ and $\Psi$ has mean entropy 0.927~bits (out of 4~bits) for correct predictions compared to 1.896~bits for incorrect predictions which, along with entropy histogram shapes, shows the model helpfully indicates where it is uncertain. Experiment 2 investigates epistemic uncertainties as well as aleatoric using Monte Carlo dropout (MCD). It compares models on both $\Phi$ and $\Psi$ with models trained on x-vectors ($X$), before applying Kalman filter smoothing on epistemic uncertainties for resegmentation and model ensembles. While the two models on $X$ (DERs 10.23\% and 9.74\%) outperform those on $\Phi$ and $\Psi$ (DER 17.85\%) after their individual Kalman filter smoothing, combining them using a Kalman filter smoothing method improves the DER to 9.29\%. Aleatoric uncertainties are higher for incorrect predictions. Both Experiments show models on $\Phi$ do not distinguish overlapping speakers as well as anticipated. However, Experiment 2 shows model ensembles do better with overlapping speakers than individual models do.