 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Classifier for COVID-19 Misinformation Detection Using BERT: a Study on Indonesian Tweets
Paper and Code
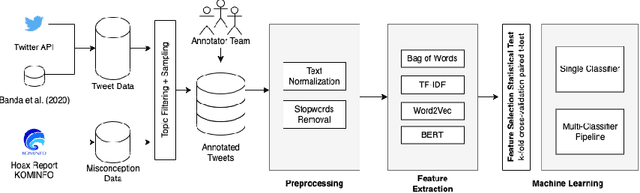


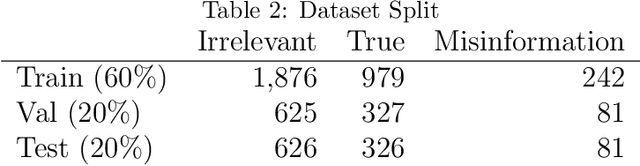
The COVID-19 pandemic has caused globally significant impacts since the beginning of 2020. This brought a lot of confusion to society, especially due to the spread of misinformation through social media. Although there were already several studies related to the detection of misinformation in social media data, most studies focused on the English dataset. Research on COVID-19 misinformation detection in Indonesia is still scarce. Therefore, through this research, we collect and annotate datasets for Indonesian and build prediction models for detecting COVID-19 misinformation by considering the tweet's relevance. The dataset construction is carried out by a team of annotators who labeled the relevance and misinformation of the tweet data. In this study, we propose the two-stage classifier model using IndoBERT pre-trained language model for the Tweet misinformation detection task. We also experiment with several other baseline models for text classification. The experimental results show that the combination of the BERT sequence classifier for relevance prediction and Bi-LSTM for misinformation detection outperformed other machine learning models with an accuracy of 87.02%. Overall, the BERT utilization contributes to the higher performance of most prediction models. We release a high-quality COVID-19 misinformation Tweet corpus in the Indonesian language, indicated by the high inter-annotator agreement.