 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer of knowledge among instruments in automatic music transcription
Paper and Code


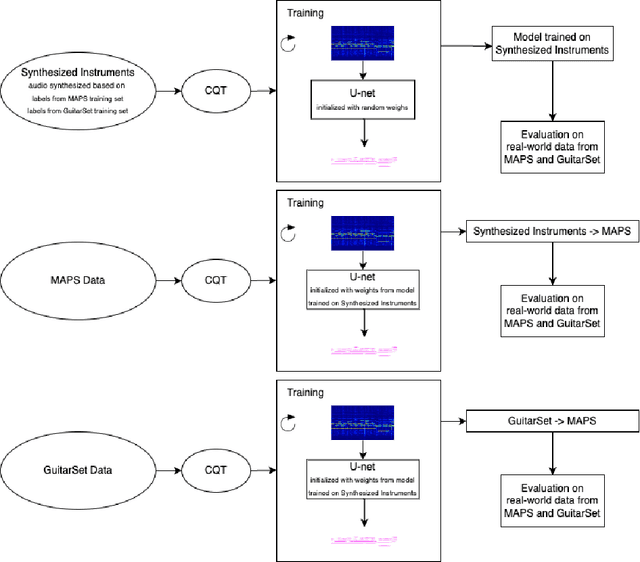

Automatic music transcription (AMT) is one of the most challenging tasks in the music information retrieval domain. It is the process of converting an audio recording of music into a symbolic representation containing information about the notes, chords, and rhythm. Current research in this domain focuses on developing new models based on transformer architecture or using methods to perform semi-supervised training, which gives outstanding results, but the computational cost of training such models is enormous. This work shows how to employ easily generated synthesized audio data produced by software synthesizers to train a universal model. It is a good base for further transfer learning to quickly adapt transcription model for other instruments. Achieved results prove that using synthesized data for training may be a good base for pretraining general-purpose models, where the task of transcription is not focused on one instrument.