 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Universal Vocoders with Feature Smoothing-Based Augmentation Methods for High-Quality TTS Systems
Paper and Code

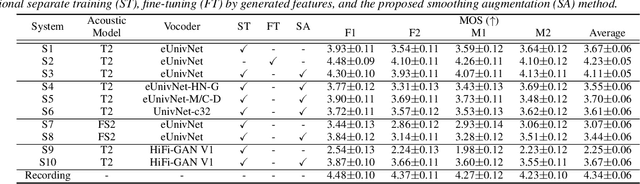


While universal vocoders have achieved proficient waveform generation across diverse voices, their integration into text-to-speech (TTS) tasks often results in degraded synthetic quality. To address this challenge, we present a novel augmentation technique for training universal vocoders. Our training scheme randomly applies linear smoothing filters to input acoustic features, facilitating vocoder generalization across a wide range of smoothings. It significantly mitigates the training-inference mismatch, enhancing the naturalness of synthetic output even when the acoustic model produces overly smoothed features. Notably, our method is applicable to any vocoder without requiring architectural modifications or dependencies on specific acoustic models. The experimental results validate the superiority of our vocoder over conventional methods, achieving 11.99% and 12.05% improvements in mean opinion scores when integrated with Tacotron 2 and FastSpeech 2 TTS acoustic models, respectively.