Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a T5 Using Lab-sized Resources
Paper and Code

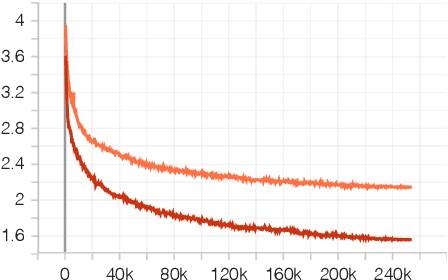
Training large neural language models on large datasets is resource- and time-intensive. These requirements create a barrier to entry, where those with fewer resources cannot build competitive models. This paper presents various techniques for making it possible to (a) train a large language model using resources that a modest research lab might have, and (b) train it in a reasonable amount of time. We provide concrete recommendations for practitioners, which we illustrate with a case study: a T5 model for Danish, the first for this language.
View paper on