Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding End-of-trip Instructions in a Taxi Ride Scenario
Paper and Code
Jul 11, 2018

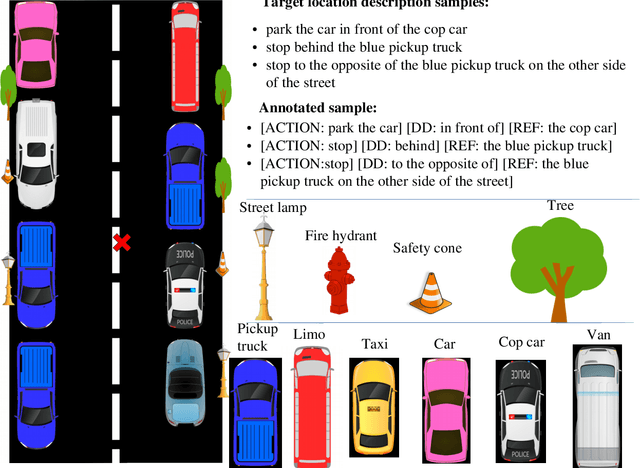
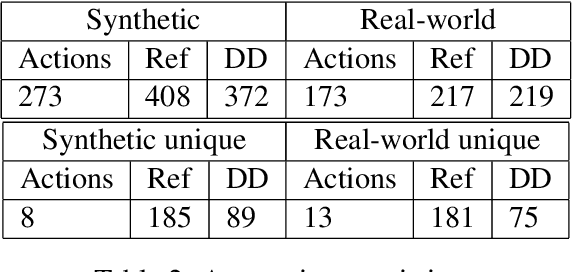
We introduce a dataset containing human-authored descriptions of target locations in an "end-of-trip in a taxi ride" scenario. We describe our data collection method and a novel annotation scheme that supports understanding of such descriptions of target locations. Our dataset contains target location descriptions for both synthetic and real-world images as well as visual annotations (ground truth labels, dimensions of vehicles and objects, coordinates of the target location,distance and direction of the target location from vehicles and objects) that can be used in various visual and language tasks. We also perform a pilot experiment on how the corpus could be applied to visual reference resolution in this domain.
* to appear in Fourteenth Joint ACL - ISO Workshop on Interoperable
Semantic Annotation, Corresponding author: Ramesh Manuvinakurike
View paper on