Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Asymptotic Optimality with Conditioned Stochastic Gradient Descent
Paper and Code
Jun 04, 2020
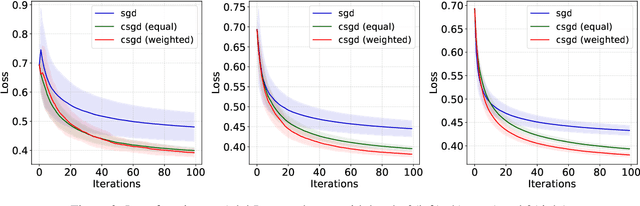


In this paper, we investigate a general class of stochastic gradient descent (SGD) algorithms, called conditioned SGD, based on a preconditioning of the gradient direction. Under some mild assumptions, namely the $L$-smoothness of the objective function and some weak growth condition on the noise, we establish the almost sure convergence and the asymptotic normality for a broad class of conditioning matrices. In particular, when the conditioning matrix is an estimate of the inverse Hessian at the optimal point, the algorithm is proved to be asymptotically optimal. The benefits of this approach are validated on simulated and real datasets.
View paper on