 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Active Robotic Vision in Agriculture: A Deep Learning Approach to Visual Servoing in Occluded and Unstructured Protected Cropping Environments
Paper and Code
Aug 05, 2019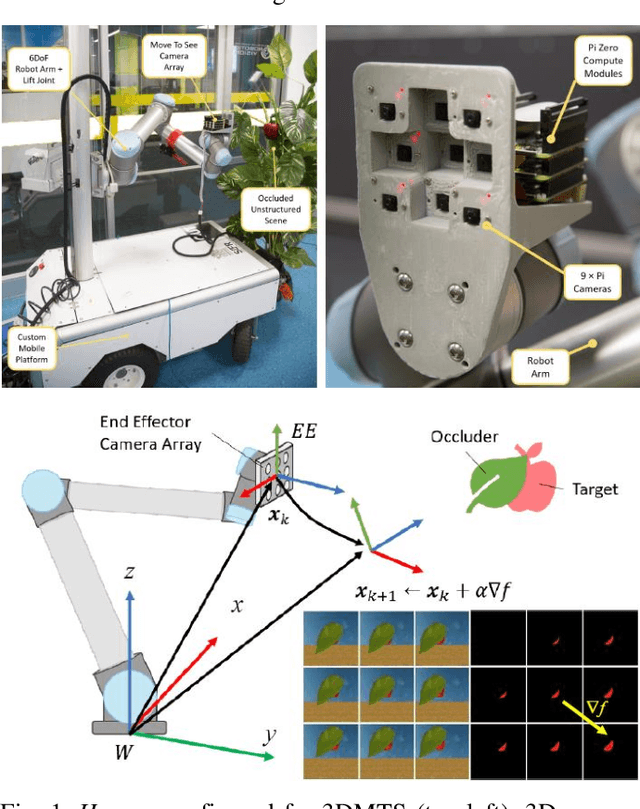
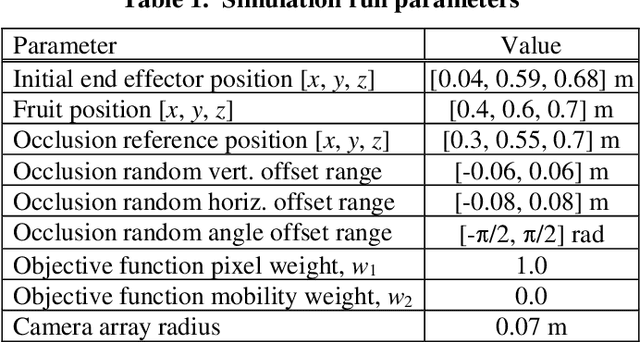

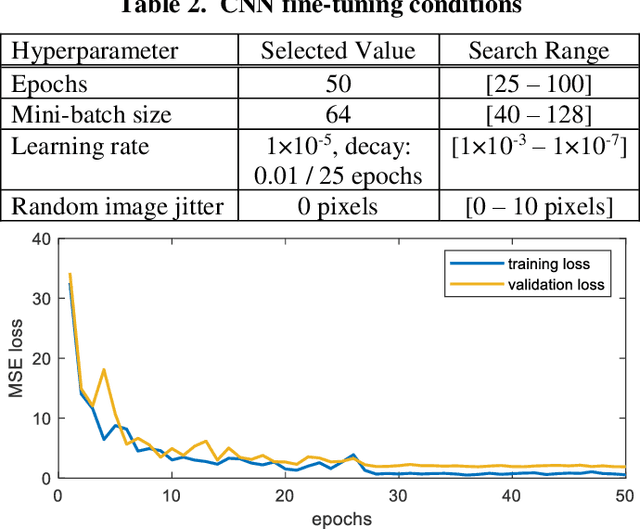
3D Move To See (3DMTS) is a mutli-perspective visual servoing method for unstructured and occluded environments, like that encountered in robotic crop harvesting. This paper presents a deep learning method, Deep-3DMTS for creating a single-perspective approach for 3DMTS through the use of a Convolutional Neural Network (CNN). The novel method is developed and validated via simulation against the standard 3DMTS approach. The Deep-3DMTS approach is shown to have performance equivalent to the standard 3DMTS baseline in guiding the end effector of a robotic arm to improve the view of occluded fruit (sweet peppers): end effector final position within 11.4 mm of the baseline; and an increase in fruit size in the image by a factor of 17.8 compared to the baseline of 16.8 (avg.).