 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Deep Improviser: a prototype deep learning post-tonal free music generator
Paper and Code
Dec 21, 2017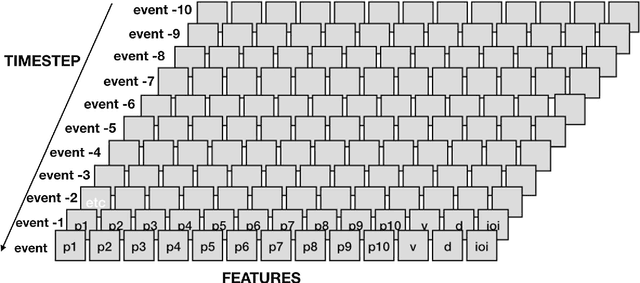
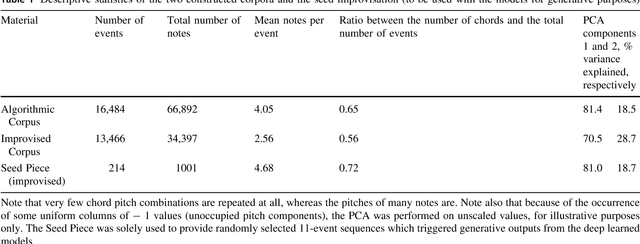

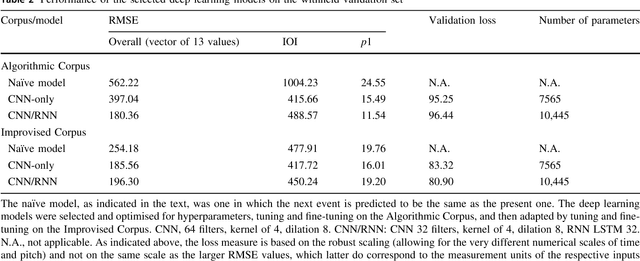
Two modest-sized symbolic corpora of post-tonal and post-metric keyboard music have been constructed, one algorithmic, the other improvised. Deep learning models of each have been trained and largely optimised. Our purpose is to obtain a model with sufficient generalisation capacity that in response to a small quantity of separate fresh input seed material, it can generate outputs that are distinctive, rather than recreative of the learned corpora or the seed material. This objective has been first assessed statistically, and as judged by k-sample Anderson-Darling and Cramer tests, has been achieved. Music has been generated using the approach, and informal judgements place it roughly on a par with algorithmic and composed music in related forms. Future work will aim to enhance the model such that it can be evaluated in relation to expression, meaning and utility in real-time performance.