 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward A Fine-Grained Analysis of Distribution Shifts in MSMARCO
Paper and Code

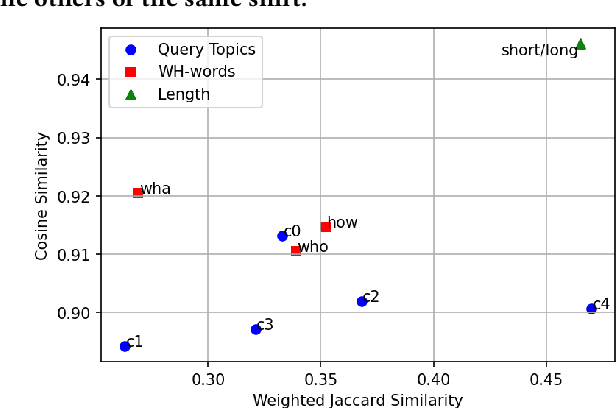
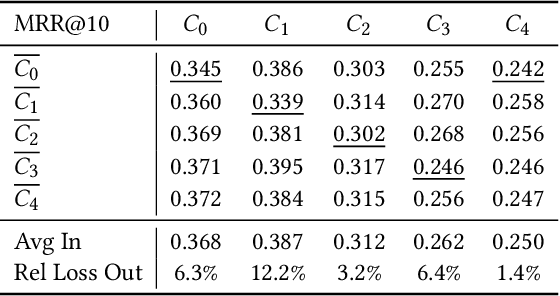

Recent IR approaches based on Pretrained Language Models (PLM) have now largely outperformed their predecessors on a variety of IR tasks. However, what happens to learned word representations with distribution shifts remains unclear. Recently, the BEIR benchmark was introduced to assess the performance of neural rankers in zero-shot settings and revealed deficiencies for several models. In complement to BEIR, we propose to control \textit{explicitly} distribution shifts. We selected different query subsets leading to different distribution shifts: short versus long queries, wh-words types of queries and 5 topic-based clusters. Then, we benchmarked state of the art neural rankers such as dense Bi-Encoder, SPLADE and ColBERT under these different training and test conditions. Our study demonstrates that it is possible to design distribution shift experiments within the MSMARCO collection, and that the query subsets we selected constitute an additional benchmark to better study factors of generalization for various models.