 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Grouper: An Agglomerative Clustering Approach to Topic Modeling
Paper and Code
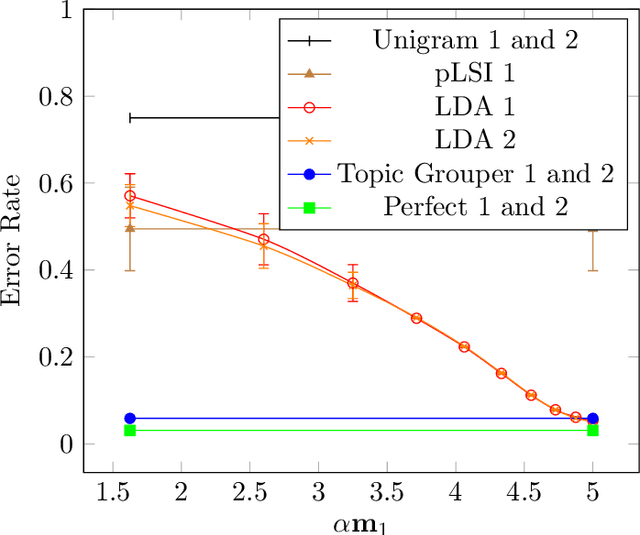
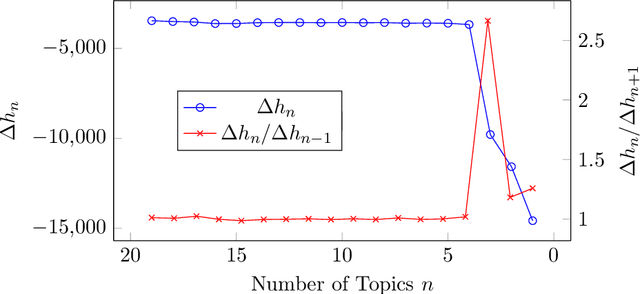


We introduce Topic Grouper as a complementary approach in the field of probabilistic topic modeling. Topic Grouper creates a disjunctive partitioning of the training vocabulary in a stepwise manner such that resulting partitions represent topics. It is governed by a simple generative model, where the likelihood to generate the training documents via topics is optimized. The algorithm starts with one-word topics and joins two topics at every step. It therefore generates a solution for every desired number of topics ranging between the size of the training vocabulary and one. The process represents an agglomerative clustering that corresponds to a binary tree of topics. A resulting tree may act as a containment hierarchy, typically with more general topics towards the root of tree and more specific topics towards the leaves. Topic Grouper is not governed by a background distribution such as the Dirichlet and avoids hyper parameter optimizations. We show that Topic Grouper has reasonable predictive power and also a reasonable theoretical and practical complexity. Topic Grouper can deal well with stop words and function words and tends to push them into their own topics. Also, it can handle topic distributions, where some topics are more frequent than others. We present typical examples of computed topics from evaluation datasets, where topics appear conclusive and coherent. In this context, the fact that each word belongs to exactly one topic is not a major limitation; in some scenarios this can even be a genuine advantage, e.g.~a related shopping basket analysis may aid in optimizing groupings of articles in sales catalogs.