 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo what extent should we trust AI models when they extrapolate?
Paper and Code
Jan 27, 2022

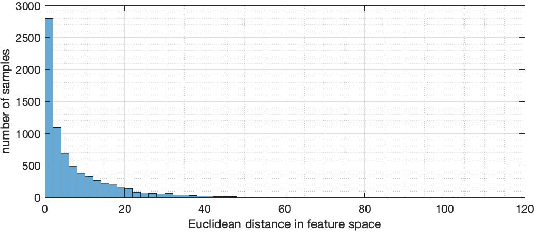
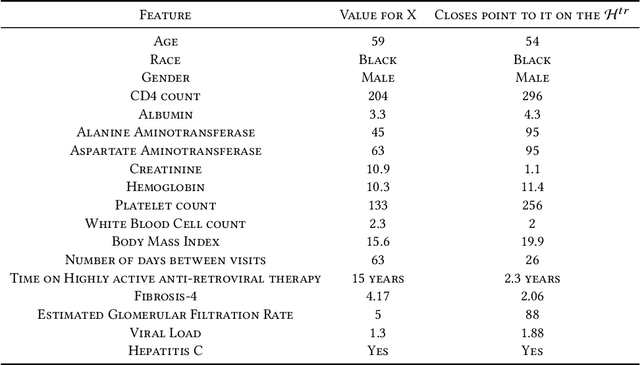
Many applications affecting human lives rely on models that have come to be known under the umbrella of machine learning and artificial intelligence. These AI models are usually complicated mathematical functions that map from an input space to an output space. Stakeholders are interested to know the rationales behind models' decisions and functional behavior. We study this functional behavior in relation to the data used to create the models. On this topic, scholars have often assumed that models do not extrapolate, i.e., they learn from their training samples and process new input by interpolation. This assumption is questionable: we show that models extrapolate frequently; the extent of extrapolation varies and can be socially consequential. We demonstrate that extrapolation happens for a substantial portion of datasets more than one would consider reasonable. How can we trust models if we do not know whether they are extrapolating? Given a model trained to recommend clinical procedures for patients, can we trust the recommendation when the model considers a patient older or younger than all the samples in the training set? If the training set is mostly Whites, to what extent can we trust its recommendations about Black and Hispanic patients? Which dimension (race, gender, or age) does extrapolation happen? Even if a model is trained on people of all races, it still may extrapolate in significant ways related to race. The leading question is, to what extent can we trust AI models when they process inputs that fall outside their training set? This paper investigates several social applications of AI, showing how models extrapolate without notice. We also look at different sub-spaces of extrapolation for specific individuals subject to AI models and report how these extrapolations can be interpreted, not mathematically, but from a humanistic point of view.