 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Two Regimes of Deep Network Training
Paper and Code
Feb 24, 2020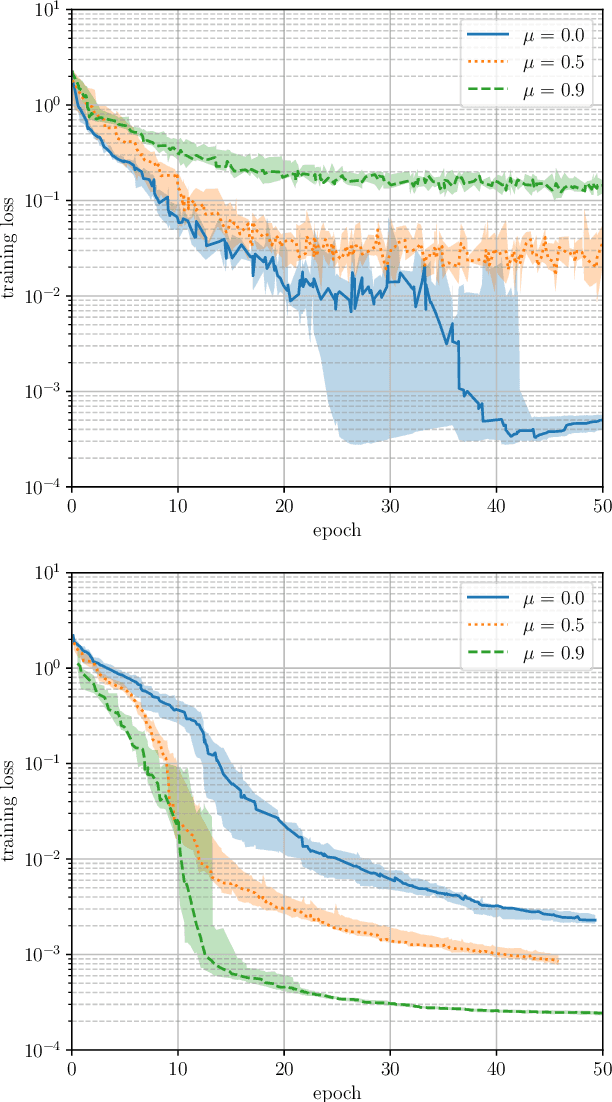
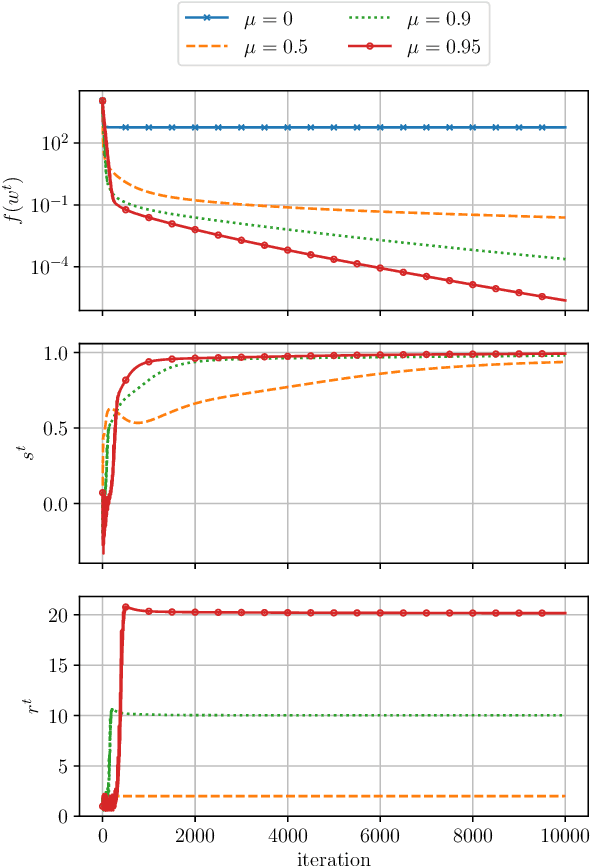

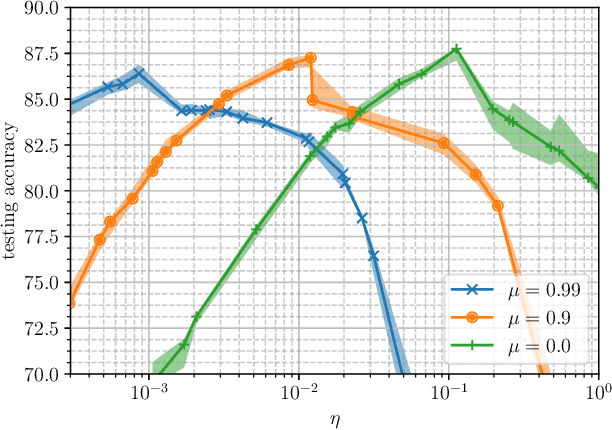
Learning rate schedule has a major impact on the performance of deep learning models. Still, the choice of a schedule is often heuristical. We aim to develop a precise understanding of the effects of different learning rate schedules and the appropriate way to select them. To this end, we isolate two distinct phases of training, the first, which we refer to as the "large-step" regime, exhibits a rather poor performance from an optimization point of view but is the primary contributor to model generalization; the latter, "small-step" regime exhibits much more "convex-like" optimization behavior but used in isolation produces models that generalize poorly. We find that by treating these regimes separately-and em specializing our training algorithm to each one of them, we can significantly simplify learning rate schedules.