 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe role of semantics in mining frequent patterns from knowledge bases in description logics with rules
Paper and Code
Apr 01, 2010
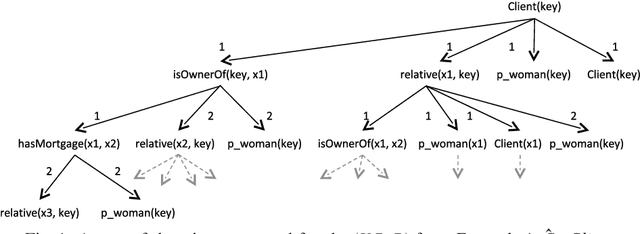

We propose a new method for mining frequent patterns in a language that combines both Semantic Web ontologies and rules. In particular we consider the setting of using a language that combines description logics with DL-safe rules. This setting is important for the practical application of data mining to the Semantic Web. We focus on the relation of the semantics of the representation formalism to the task of frequent pattern discovery, and for the core of our method, we propose an algorithm that exploits the semantics of the combined knowledge base. We have developed a proof-of-concept data mining implementation of this. Using this we have empirically shown that using the combined knowledge base to perform semantic tests can make data mining faster by pruning useless candidate patterns before their evaluation. We have also shown that the quality of the set of patterns produced may be improved: the patterns are more compact, and there are fewer patterns. We conclude that exploiting the semantics of a chosen representation formalism is key to the design and application of (onto-)relational frequent pattern discovery methods. Note: To appear in Theory and Practice of Logic Programming (TPLP)