 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe QLBS Q-Learner Goes NuQLear: Fitted Q Iteration, Inverse RL, and Option Portfolios
Paper and Code
Jan 17, 2018


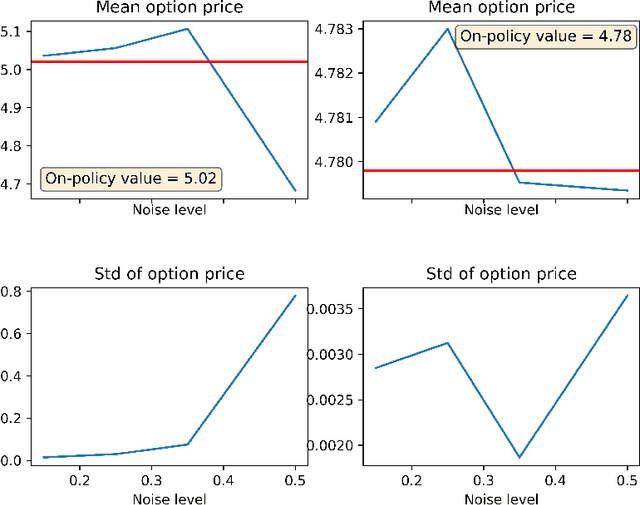
The QLBS model is a discrete-time option hedging and pricing model that is based on Dynamic Programming (DP) and Reinforcement Learning (RL). It combines the famous Q-Learning method for RL with the Black-Scholes (-Merton) model's idea of reducing the problem of option pricing and hedging to the problem of optimal rebalancing of a dynamic replicating portfolio for the option, which is made of a stock and cash. Here we expand on several NuQLear (Numerical Q-Learning) topics with the QLBS model. First, we investigate the performance of Fitted Q Iteration for a RL (data-driven) solution to the model, and benchmark it versus a DP (model-based) solution, as well as versus the BSM model. Second, we develop an Inverse Reinforcement Learning (IRL) setting for the model, where we only observe prices and actions (re-hedges) taken by a trader, but not rewards. Third, we outline how the QLBS model can be used for pricing portfolios of options, rather than a single option in isolation, thus providing its own, data-driven and model independent solution to the (in)famous volatility smile problem of the Black-Scholes model.