 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pitfall of Evaluating Performance on Emerging AI Accelerators
Paper and Code
Nov 08, 2019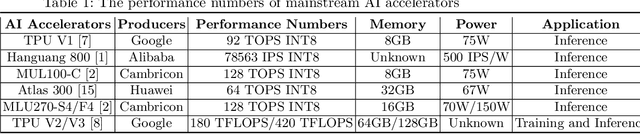

In recent years, domain-specific hardware has brought significant performance improvements in deep learning (DL). Both industry and academia only focus on throughput when evaluating these AI accelerators, which usually are custom ASICs deployed in datacenter to speed up the inference phase of DL workloads. Pursuing higher hardware throughput such as OPS (Operation Per Second) using various optimizations seems to be their main design target. However, they ignore the importance of accuracy in the DL nature. Motivated by this, this paper argue that a single throughput metric can not comprehensively reflect the real-world performance of AI accelerators. To reveal this pitfall, we evaluates several frequently-used optimizations on a typical AI accelerator and quantifies their impact on accuracy and throughout under representative DL inference workloads. Based on our experimental results, we find that some optimizations cause significant loss on accuracy in some workloads, although it can improves the throughout. Furthermore, our results show the importance of end-to-end evaluation in DL.