 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multiple Subnetwork Hypothesis: Enabling Multidomain Learning by Isolating Task-Specific Subnetworks in Feedforward Neural Networks
Paper and Code
Jul 18, 2022
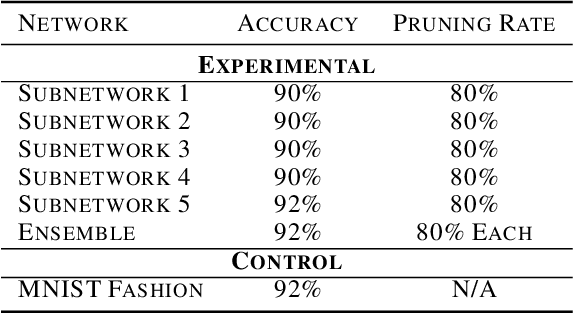


Neural networks have seen an explosion of usage and research in the past decade, particularly within the domains of computer vision and natural language processing. However, only recently have advancements in neural networks yielded performance improvements beyond narrow applications and translated to expanded multitask models capable of generalizing across multiple data types and modalities. Simultaneously, it has been shown that neural networks are overparameterized to a high degree, and pruning techniques have proved capable of significantly reducing the number of active weights within the network while largely preserving performance. In this work, we identify a methodology and network representational structure which allows a pruned network to employ previously unused weights to learn subsequent tasks. We employ these methodologies on well-known benchmarking datasets for testing purposes and show that networks trained using our approaches are able to learn multiple tasks, which may be related or unrelated, in parallel or in sequence without sacrificing performance on any task or exhibiting catastrophic forgetting.