 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mondrian Process for Machine Learning
Paper and Code
Jul 18, 2015
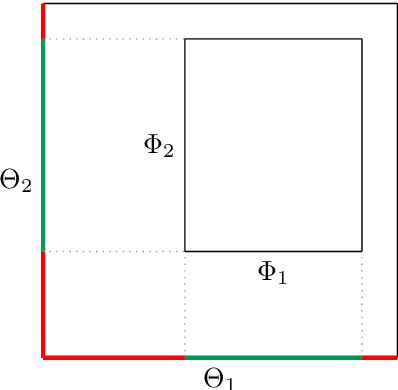
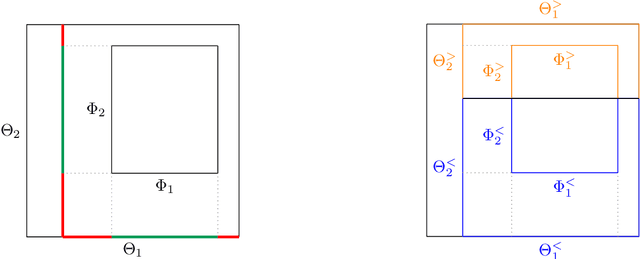
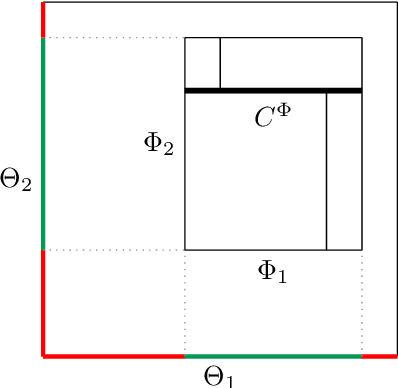
This report is concerned with the Mondrian process and its applications in machine learning. The Mondrian process is a guillotine-partition-valued stochastic process that possesses an elegant self-consistency property. The first part of the report uses simple concepts from applied probability to define the Mondrian process and explore its properties. The Mondrian process has been used as the main building block of a clever online random forest classification algorithm that turns out to be equivalent to its batch counterpart. We outline a slight adaptation of this algorithm to regression, as the remainder of the report uses regression as a case study of how Mondrian processes can be utilized in machine learning. In particular, the Mondrian process will be used to construct a fast approximation to the computationally expensive kernel ridge regression problem with a Laplace kernel. The complexity of random guillotine partitions generated by a Mondrian process and hence the complexity of the resulting regression models is controlled by a lifetime hyperparameter. It turns out that these models can be efficiently trained and evaluated for all lifetimes in a given range at once, without needing to retrain them from scratch for each lifetime value. This leads to an efficient procedure for determining the right model complexity for a dataset at hand. The limitation of having a single lifetime hyperparameter will motivate the final Mondrian grid model, in which each input dimension is endowed with its own lifetime parameter. In this model we preserve the property that its hyperparameters can be tweaked without needing to retrain the modified model from scratch.